[Knowledge Graph] 4. SPARQL
이 글은 2021년 대학원 수업 지식 표현 연구를 중심으로 작성된 포스트이다. 수업시간에 이해한 내용을 복습하는 차원에서 적는 글이니 언제든 댓글은 환영한다🙌
- 지식 표현 연구 시리즈
이 포스팅은 Stardog Tutorial의 Learn SPARQL 내용을 담고 있습니다. 정확한 내용은 원문을 확인해주세요.
1. SPARQL이란?
SPARQL(스파클)은 RDF 트리플로 표현된 그래프 데이터를 쿼리하기위한 표준 언어이다. SPARQL Protocol and RDF Query Language의 약어이다.(이게 머선 약어고,,,😅) 시맨틱 웹 분야에서 RDF와 OWL과 함께 핵심적인 표준 언어로 자리잡고 있다.1
2. SPARQL 쿼리의 유형
SPARQL은 데이터베이스를 다루는 SQL 쿼리 언어를 접해본 적이 있다면 이해가 쉽다. 그래프 데이터에서 특정한 조건에 맞는 데이터를 가져와 테이블 형태로 보여주는 것을 질의(query)라고 한다. 그래프 데이터를 쿼리하는 표준 언어는 SPARQL이다.2 크게 4가지 유형으로 구분된다.
SELECT: 특정한 조건에 맞는 데이터를 불러올 때CONSTRUCT: 쿼리한 다음에 새로운 RDF 형태를 만들고 싶을 때 사용한다DESCRIBE: RDF 데이터에 대한 상세한 정보를 얻을 때ASK: 특정 패턴에 부합하는지 요청할 때
3. SPARQL 쿼리의 구조
PREFIX- 제일 상단에는 접두어가 위치한다.
- 어휘
dcterms와dcat을 사용하므로 상단에 접두어를 정의한다.
SELECT- ‘SELECT’ 다음에는 변수가 위치해야 한다.
- RDF 트리플(SPO 구조)이 반복되므로 이를
SPO Pattern이라 한다. - SQL에서의
SELECT (변수) WHERE (조건)과 같이 SPARQL에서도 같은 구조를 따라 쿼리를 작성한다. WHERE절에서 2줄 이상의 쿼리를 작성하는 경우에는 하나의 SPO를 작성한 후 반드시 맨 마지막에온점(.)을 찍어준다.- 변수일 경우 변수명 앞에
?을 적는다.
4. 실습: SETUP
실습은 Stardog에서 제공하는 튜토리얼에서 제공하는 비틀즈 그래프를 사용한다. 그래프 구조를 파악하는 것은 중요한데, 구조를 잘 알고 있어야 쿼리문을 작성할 수 있기 때문이다.
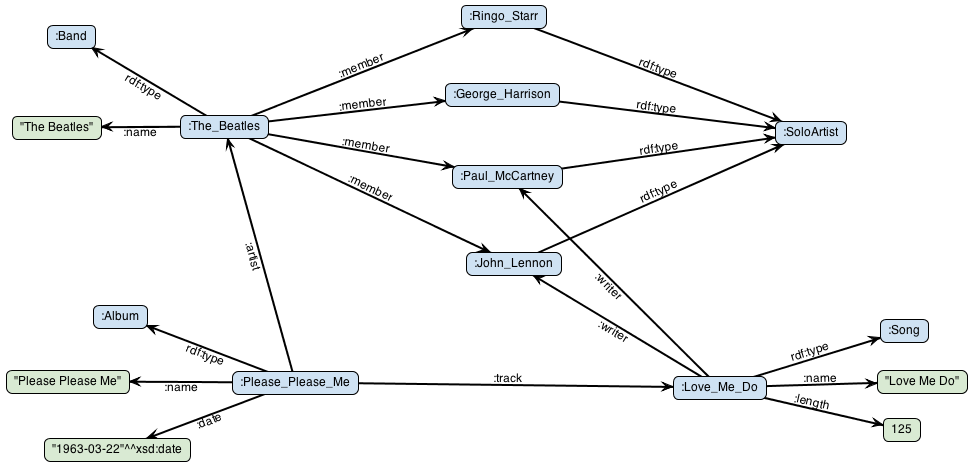
| 사진을 클릭하면 stardog tutorial 페이지로 이동한다. | ⓒ stardog |
Stardog Studio를 사용하면 쉽게 쿼리문을 실습할 수 있다. Stardog의 비틀즈 그래프는 4개의 class를 제공한다.
:Album: 비틀즈 밴드가 만든 앨범을 의미한다.:Band: 여러 명의 뮤지션들이 모인 밴드를 의미한다.:SoloArtist: 밴드를 구성하고 있는 솔로 아티스트(개인)을 의미한다.:Song: 앨범의 트랙으로 실린 개별 곡을 의미한다.
5. SELECT 쿼리
SELECT <variables>
WHERE {
<graph pattern>
}
SELECT는 2가지 요소로 구성된다. 하나는 SELECT로 쿼리를 통해 확인하고 싶은 변수를 작성한다. 다른 하나는 WHERE로, 추출할 결과에 맞는 조건문을 WHERE절 {}(curly braces) 안에 작성한다.
5.1 Triple Patterns (1)
💁🏻♀️ “SELECT를 활용하여 Album 클래스를 타입(rdf:type)로 가지고 있는 값을 출력해보자. “
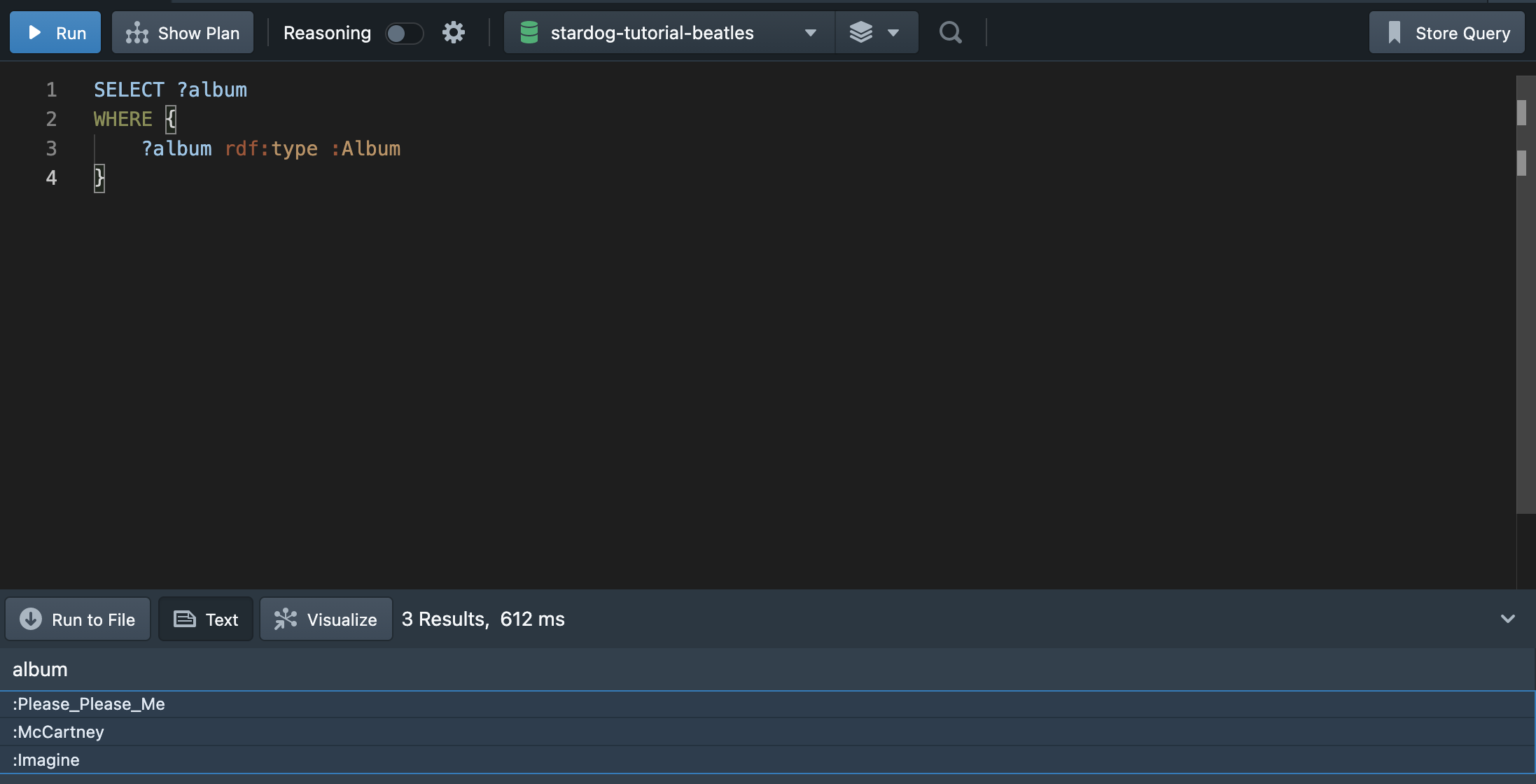
쿼리문을 분석해보자. SELECT 다음에는 ?album 변수가 위치한다. 결과로 WHERE안의 조건에 부합하는 ?album 변수를 출력하겠다는 의미이다. 따라서 WHERE절 안의 조건에는 ?album과 똑같은 변수가 존재해야 한다. ? 뒤에는 어떤 변수값이 와도 상관 없다. 하지만, 의미상 출력하고 싶은 변수 이름을 작성하면 쿼리문을 이해하기 쉽다.
WHERE 절의 조건은 S-P-O 구조를 따른다. 주어에 결과로 출력하고 싶은 ?album을 두고, 속성에는 rdf:type, 목적어에는 :Album을 둔다. 조건의 의미는 ?album이 :Album이란 클라스의 인스턴스로 가지는(rdf:type) 주어를 출력한다는 것이다. 결과는 :Please_Please_Me, :McCartney, :Imagine 앨범을 출력한다.
5.2 Triple Patterns (2)
다른 방식으로 위의 결과를 출력해보자. WHERE을 사용하지 않고도 같은 결과를 출력할 수 있다.
*(아스타리스크)를 모든 것을 가져온다는 의미이다. 이 뒤에 {} 안에 S-P-O 구조를 위와 같이 작성하면 같은 결과를 출력할 수 있다. SPARQL 언어는 소문자와 대문자를 구분하지 않으므로(case-insesitive) 소문자로 작성해도 상관 없다.(다만, 통상적으로 대문자를 사용한다.)
5.3 Basic Graph Patterns
💁🏻♀️ “Album 클래스를 인스턴스로 가진 값과 그 앨범의 아티스트의 이름까지 출력해보자.”
2개의 조건은 어떻게 쿼리문으로 작성해야 할까? 1개 이상의 트리플 구조를 통상 Basic Graph Patterns라고 한다. 2개 이상의 조건문을 작성하는 경우, 하나의 조건절이 끝날 때 온점(.)을 첨가한다.(붙이지 않으면 에러가 뜨니 주의할 것!)
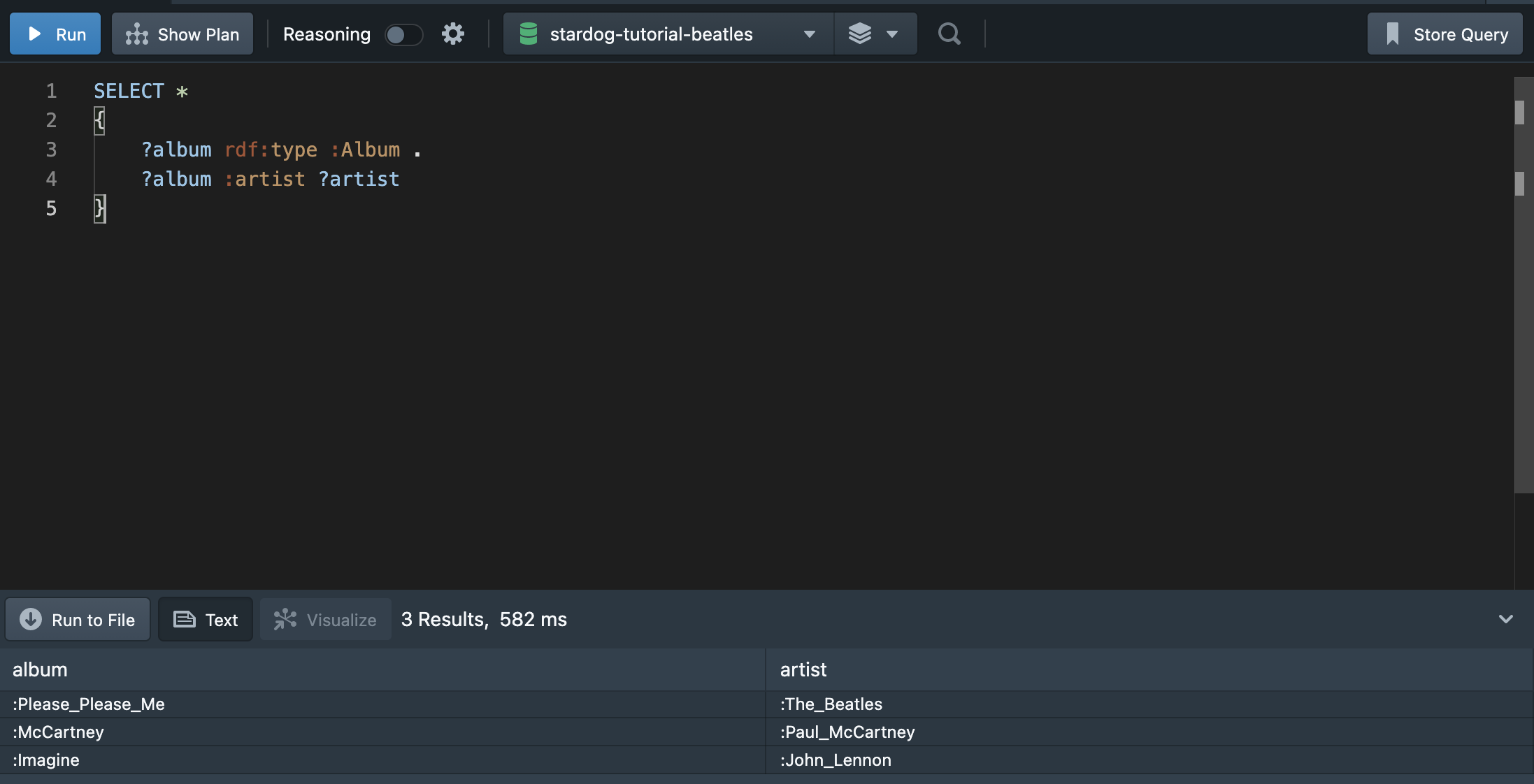
*를 사용하여 변수 ?album과 ?artist를 모두 출력하였다. 두번째 조건문은 ?album에 아티스트(:artist)라는 속성을 가지는 ?artist 변수를 출력한다는 의미이다.
SELECT ?album ?artist
WHERE {
?album a :Album .
?album :artist ?artist
}
그러나 *는 전체 데이터를 가져온다는 의미이므로, 위와 같이 출력하고 싶은 변수만을 작성하는 것이 보다 효율적인 방식이다. rdf:type은 간단히 줄여 a로 작성할 수 있다.
💁🏻♀️ “Album 클래스를 인스턴스로 가진 값과 그 앨범의 아티스트의 이름까지 출력해보자. 단, 아티스트는 솔로 아티스트여야 한다.”
지금까지 배운 것으로 위의 질문에 대한 쿼리를 작성해보자. ?artist에 조건을 달아주어 출력하면 된다.
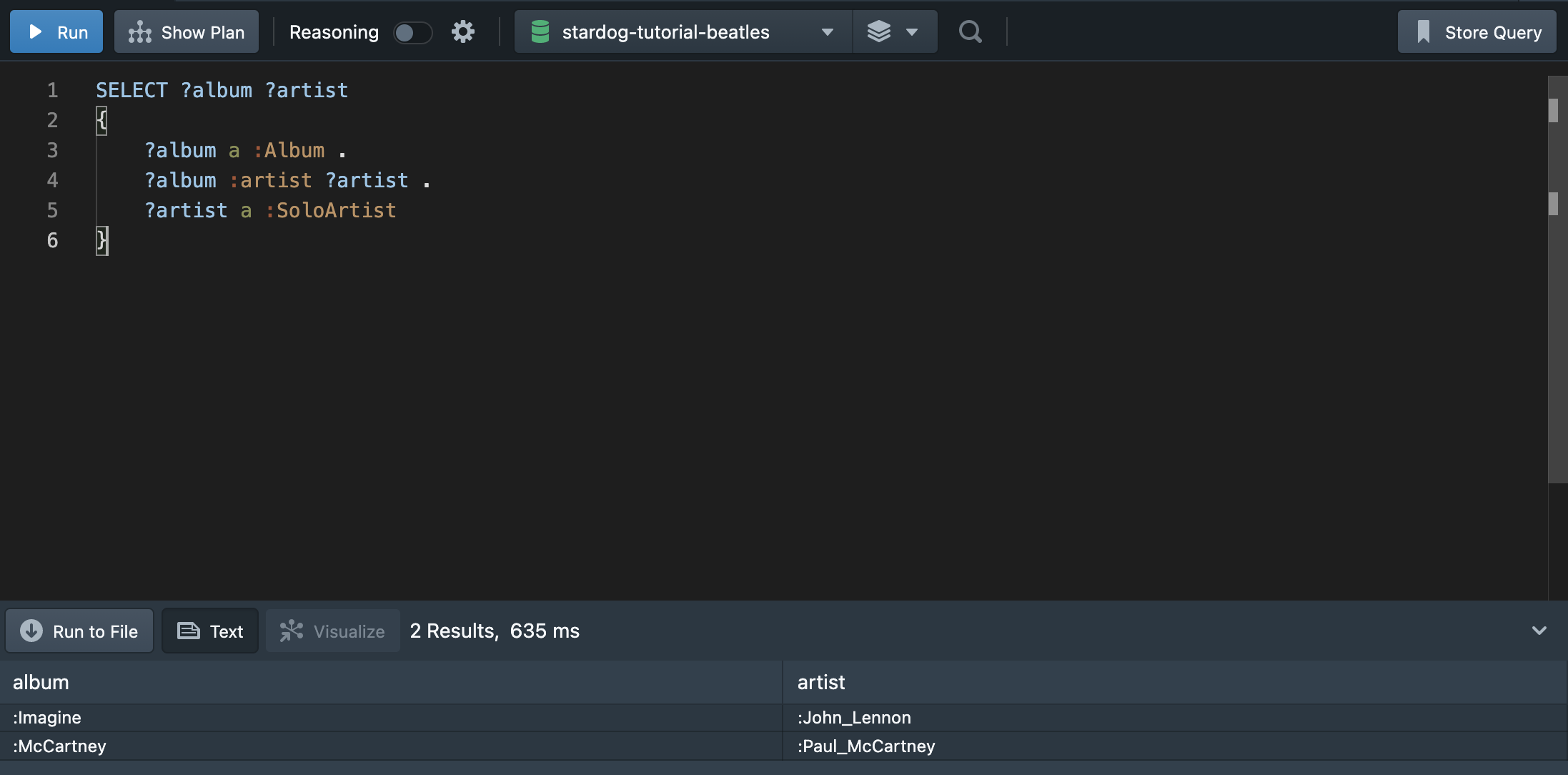
세번째 조건문으로 ?artist가 :SoloArtist의 인스턴스임을 추가하면 된다. 결과값으로 밴드인 비틀즈가 제외된 값이 출력된다.
5.4 정렬하기(Ordering Results)
💁🏻♀️ “Album 클래스를 인스턴스로 가진 값과 그 앨범의 아티스트의 이름, 앨범에 발매된 일자까지 출력해보자. 단, 발매일은 오름차순으로 출력되어야 한다.”
정렬하기는 값을 일정한 순서나 조건에 맞춰 출력되도록 한다. 먼저 발매일까지 포함하여 값이 출력되도록 해보자.
주어가 중복될 경우, 세미콜론(;)을 활용하여 더욱 간단하게 쿼리문을 작성할 수 있다. 발매일 결과를 오름차순으로 정렬하려면, ORDER BY라는 문법을 사용하면 된다.
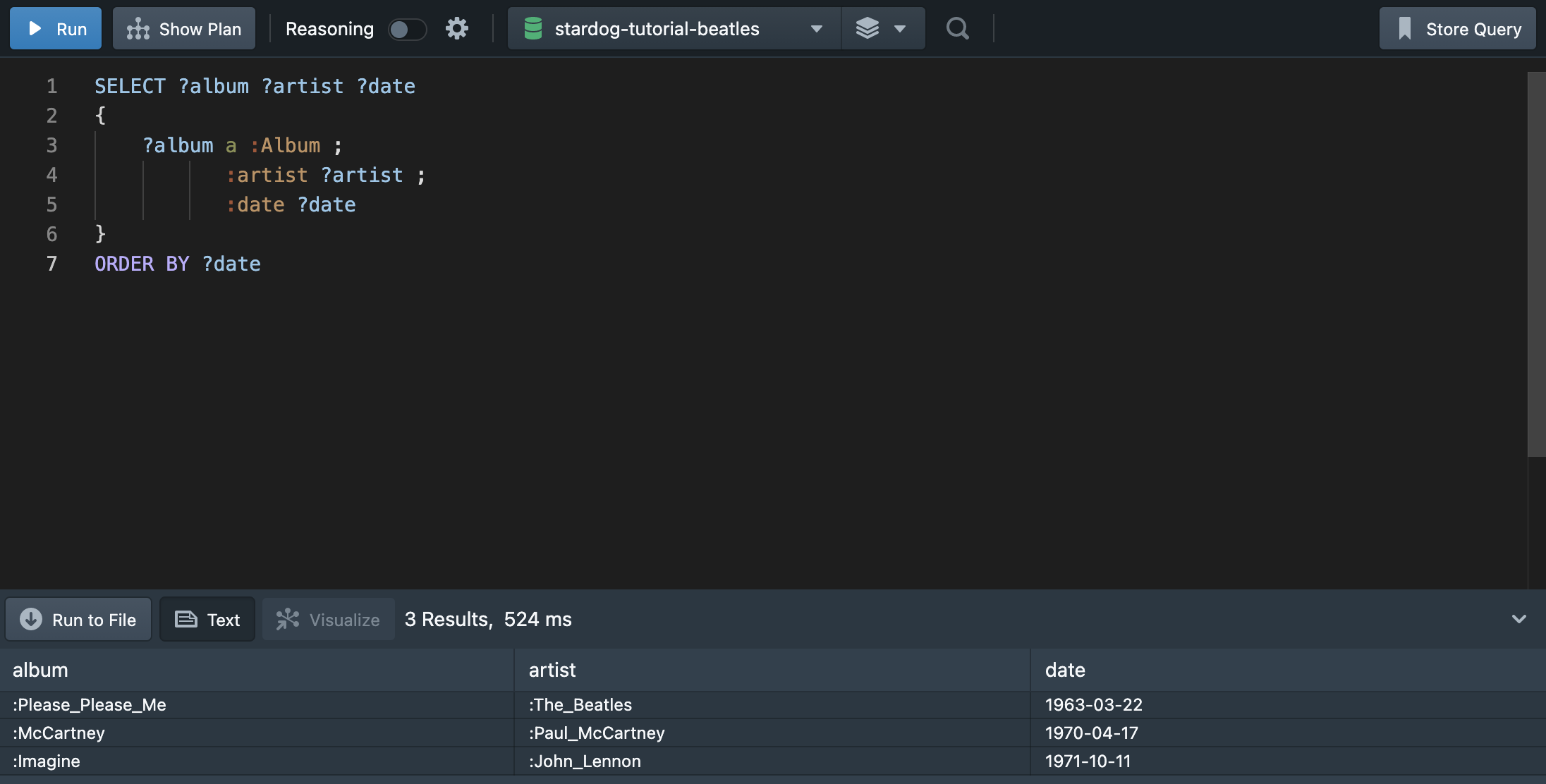
mysql에서 ORDER BY를 작성하는 것과 동일하다. 내림차순은 아래와 같이 DESC를 사용하여 정렬한다.
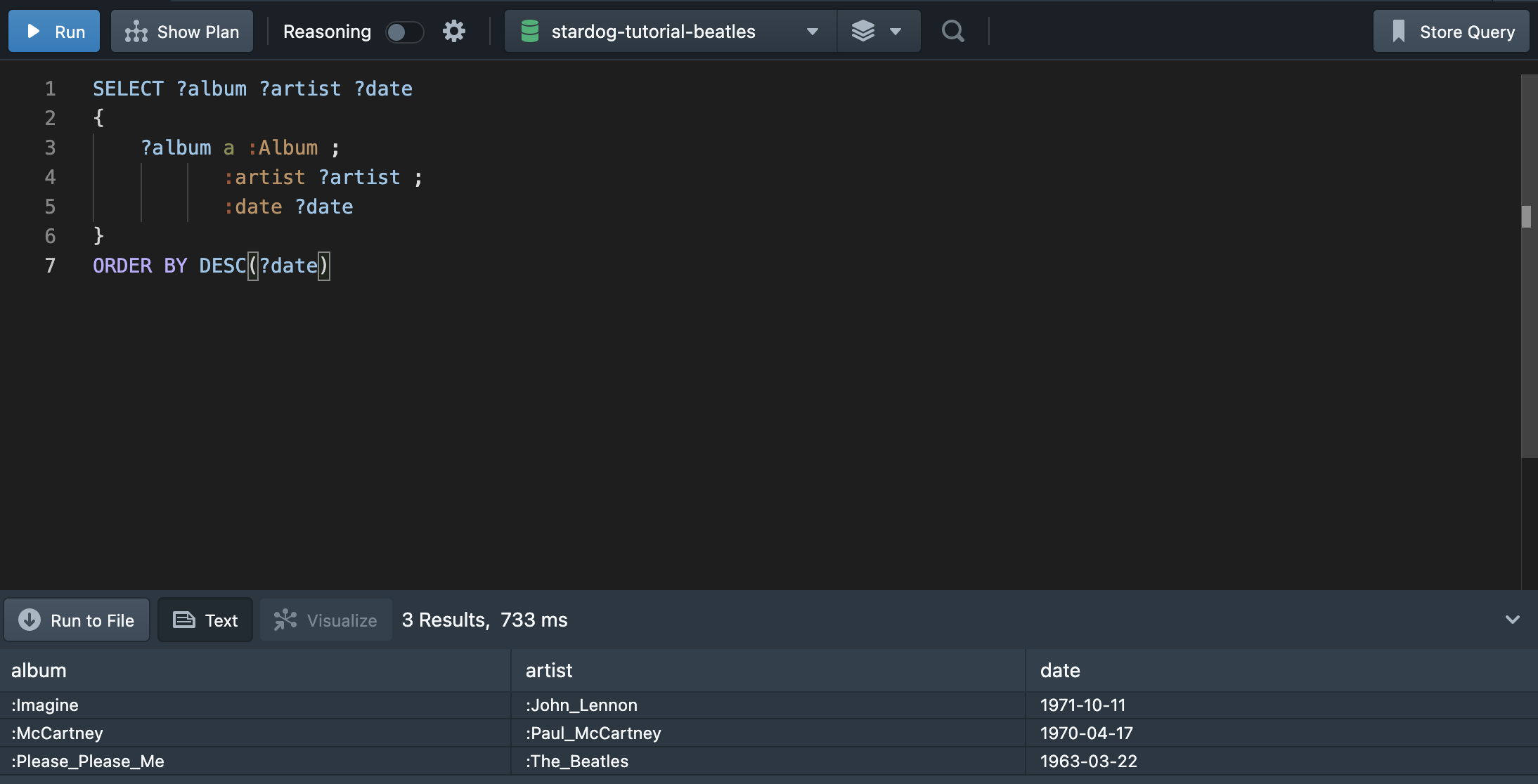
5.5 Slicing Results
너무 많은 결과가 출력될 경우에는 LIMIT을 활용해 출력되는 값을 제한할 수 있다. 가장 최신 앨범 2개만 출력해보자.
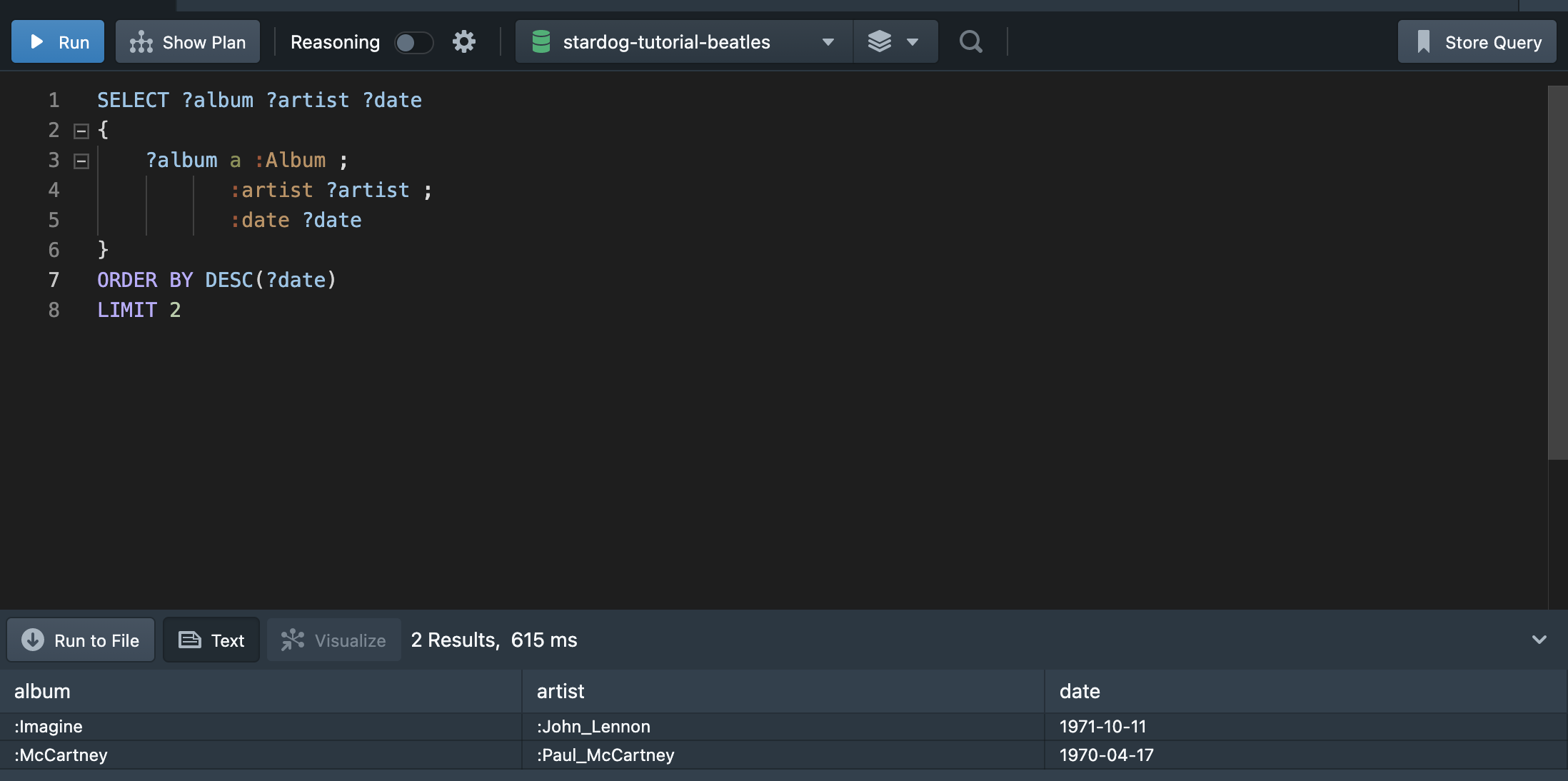
mysql과 같이 LIMIT을 활용하여 출력값을 지정해주면 된다.
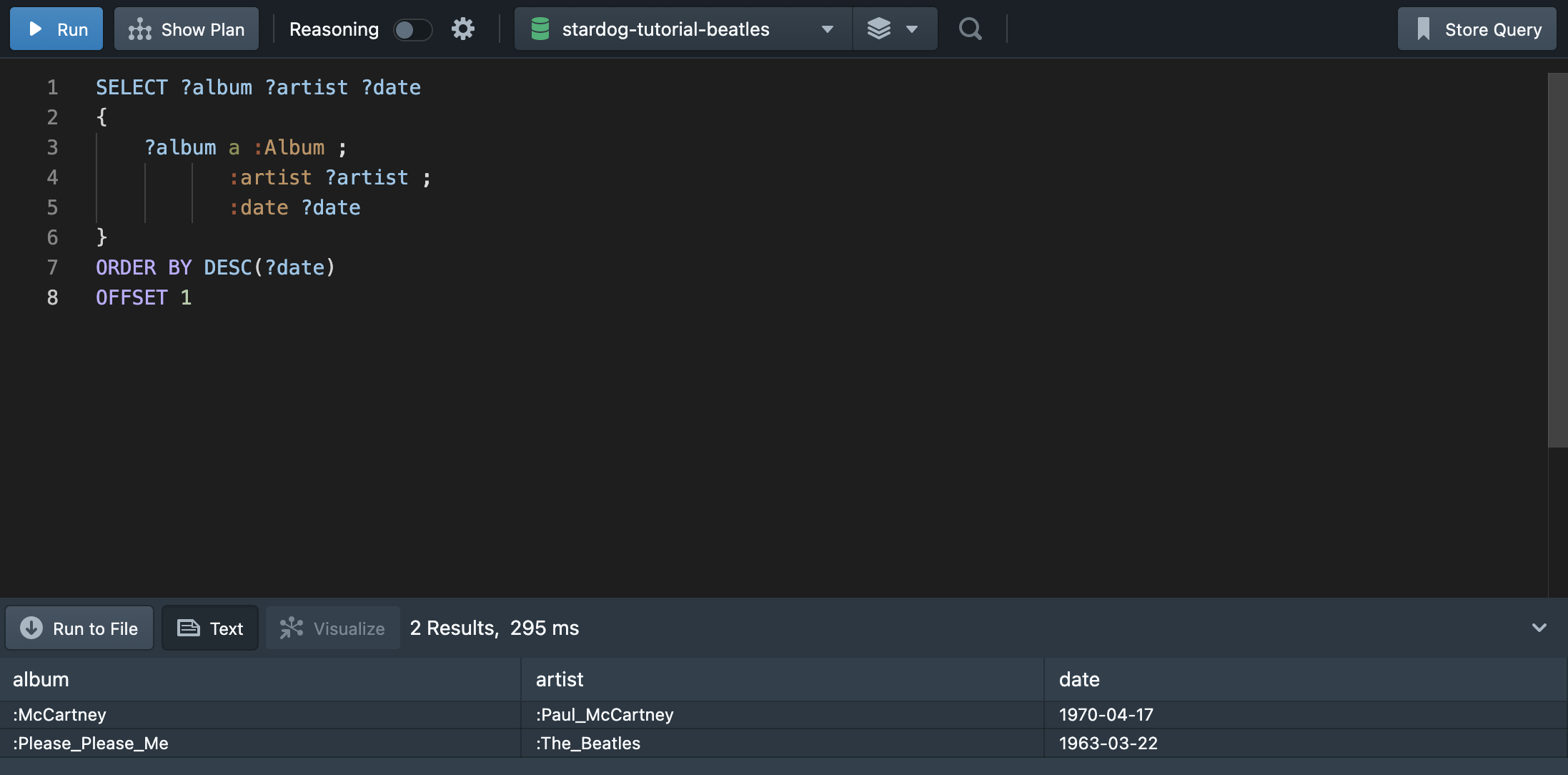
OFFSET을 활용하면 처음부터 N개의 출력값을 생략하고 결과를 가져올 수 있다. 위의 쿼리문에서는 첫번째 결과를 제외하고 나머지 2개의 값을 출력한다.
5.6 Filtering Results
SPARQL에서는 다양한 빌트인 함수를 통해 필터링할 수 있다. 연산자(operator)에 대한 정확한 의미는 W3C의 1.1 SPARQL Recommendation 문서를 통해 확인할 수 있다.
- 비교 연산자:
=,!=,<,<=,>,>= - 논리 연산자:
&&,||,! - 산술 연산자:
+,-,/,*
💁🏻♀️ “Album 클래스를 인스턴스로 가진 값과 그 앨범의 아티스트의 이름, 앨범에 발매된 일자까지 출력해보자. 단, 1970년을 포함해 그 이후로 발매된 앨범만 출력한다.”
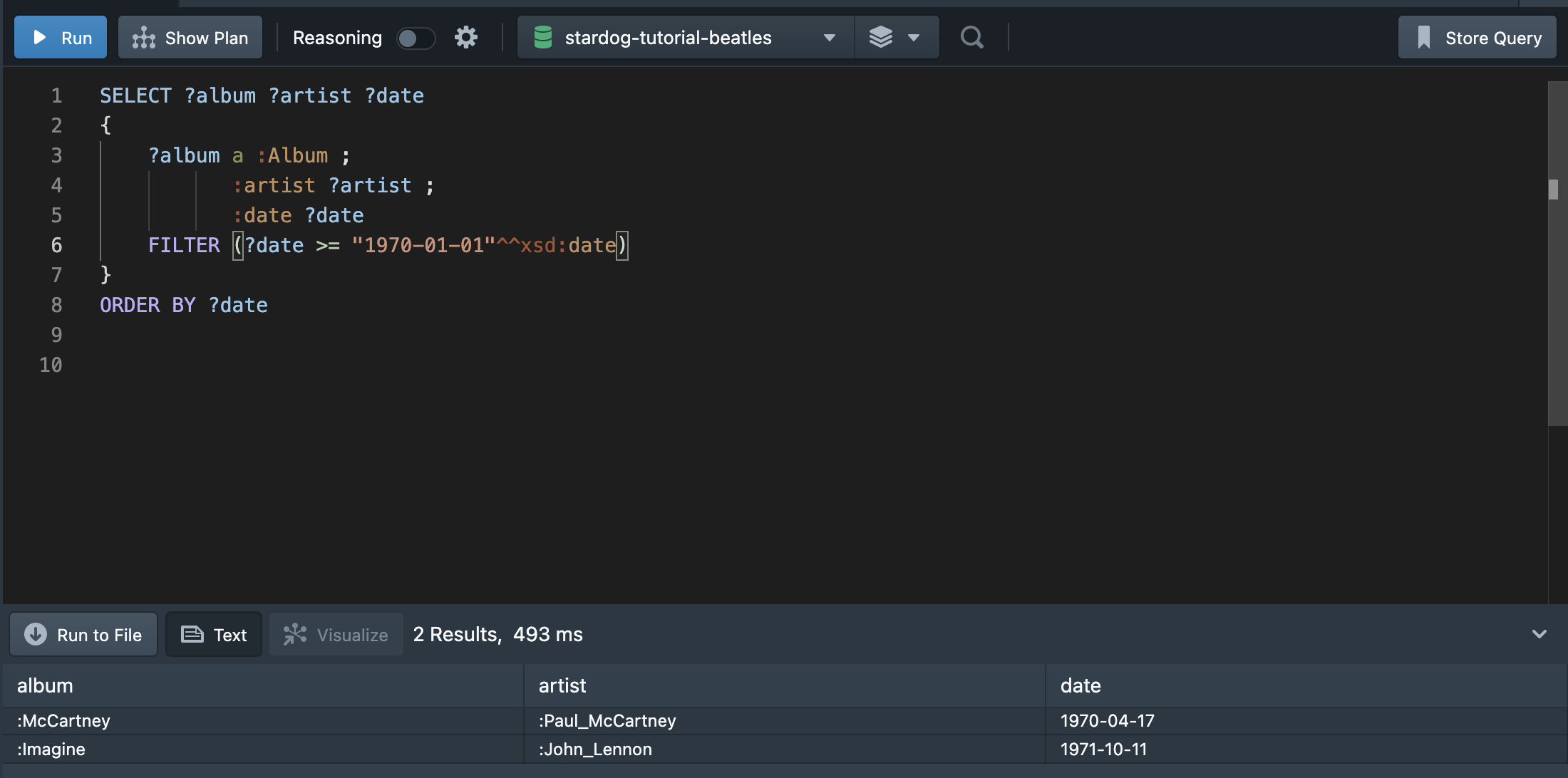
혹은 아래와 같이 ?date 값에서 연도만 비교하여 출력할 수도 있다.
SELECT ?album ?artist ?date
{
?album a :Album ;
:artist ?artist ;
:date ?date
FILTER (year(?date) >= 1970)
}
ORDER BY ?date
5.7 Binding Values
BIND 문법을 사용하여 함수 결과를 편리하게 재활용할 수 있다. 다양한 함수를 사용할 경우, BIND로 묶어 좀 더 읽기 편하게 함수를 표현할 수 있다. mysql의 AS와 기능이 비슷하다고 볼 수 있다.
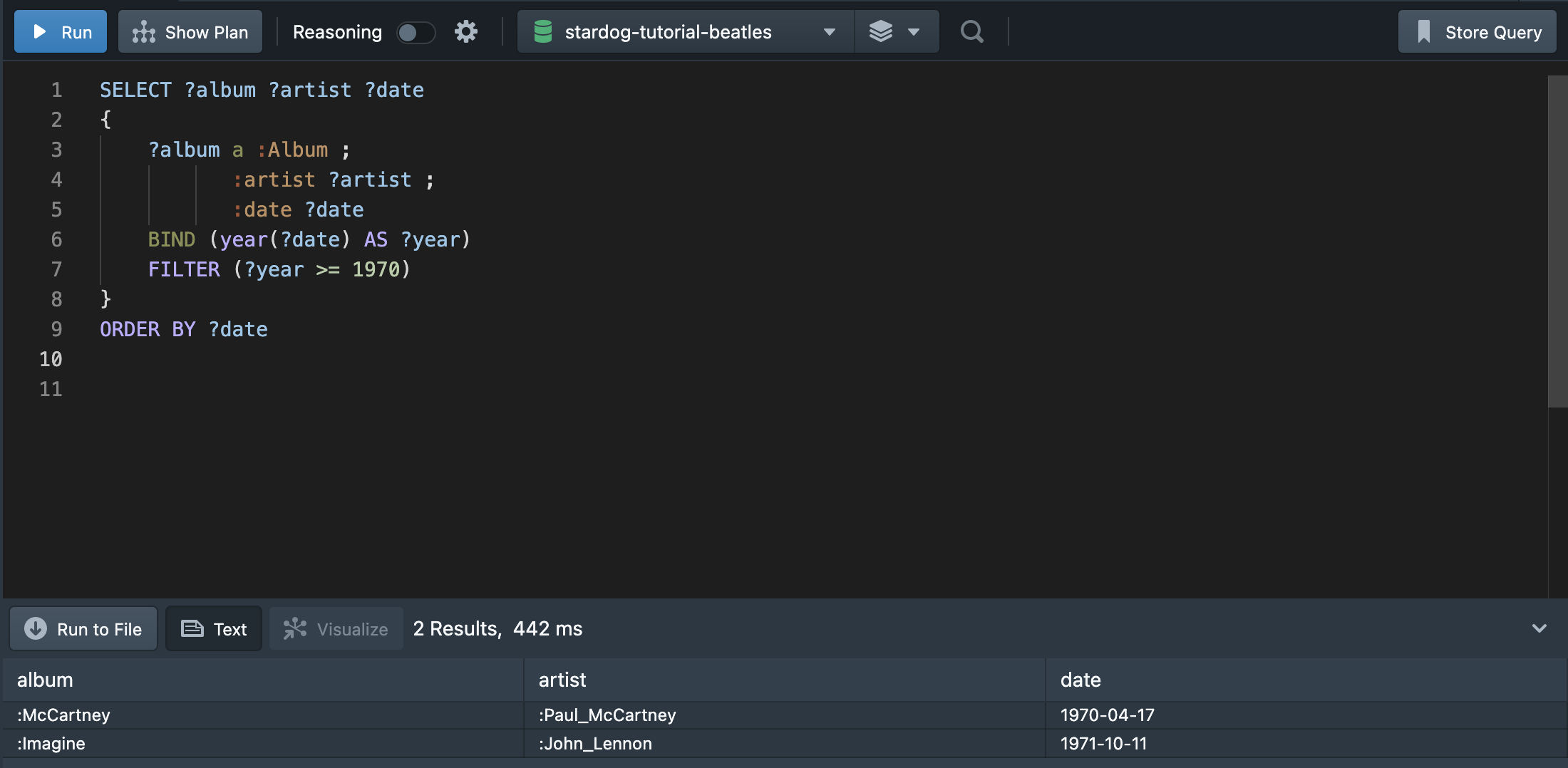
위의 쿼리문은 year(?date)를 ?year라는 변수로 묶어준 것이다. 다음 쿼리문에서는 ?year를 활용해 좀 더 간단하게 FILTER 구문을 작성할 수 있다.
5.8 Removing Duplicates
이제는 음악 그래프 데이터를 활용해 쿼리를 해보자. 비틀즈 그래프보다는 더 많은 음악 데이터들이 포함되어 있다. 아래와 같이 발매된 앨범의 연도만 출력해보자.
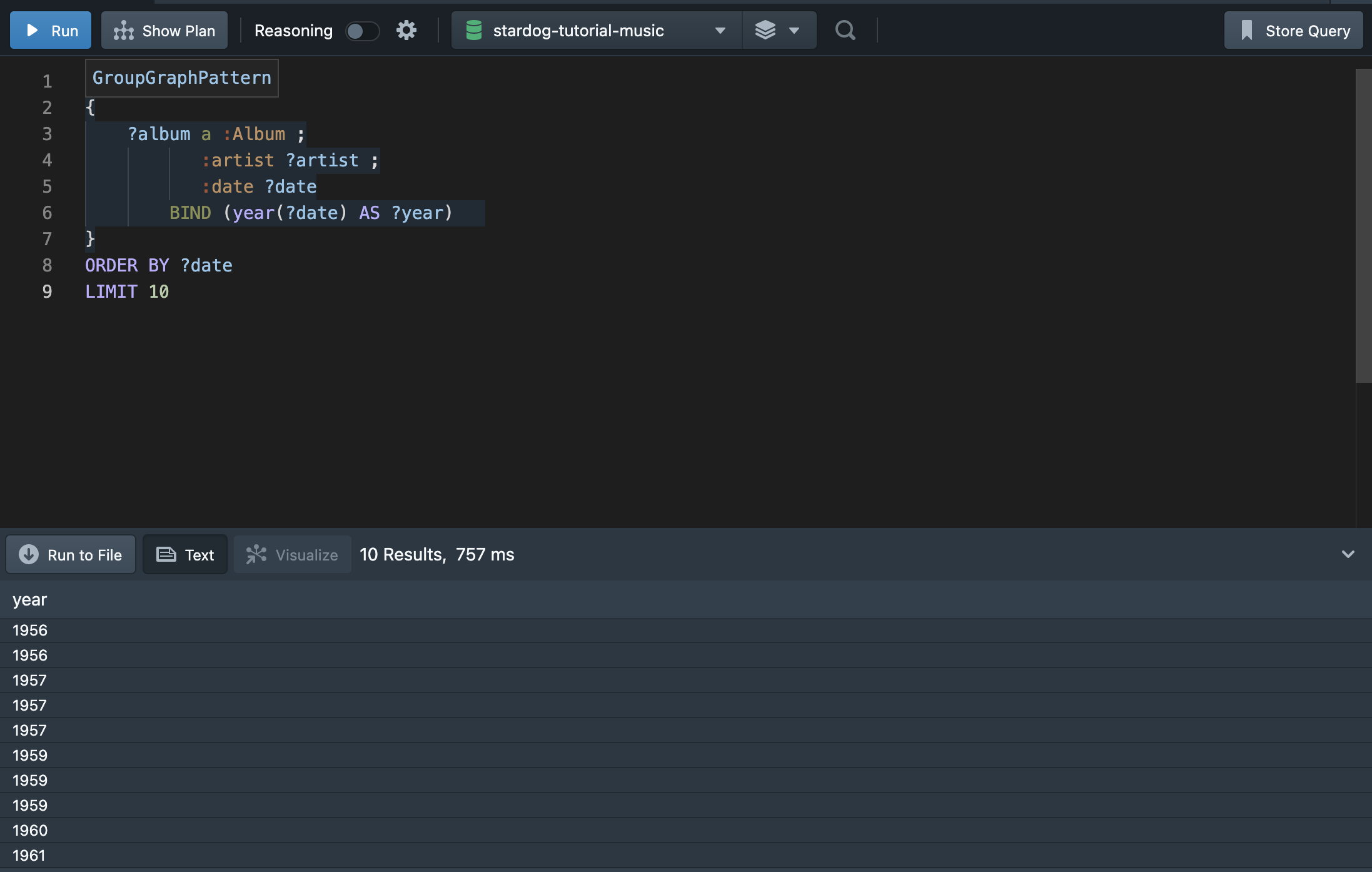
1,000개의 데이터를 포함하므로 10개만 출력해본다. 위에서 확인할 수 있듯이, 발매 연도가 중복되어 출력된다. 중복 값 없이 출력하려면 어떻게 해야 할까? mysql과 같이 DISTINCT를 활용하여 출력하면 된다.
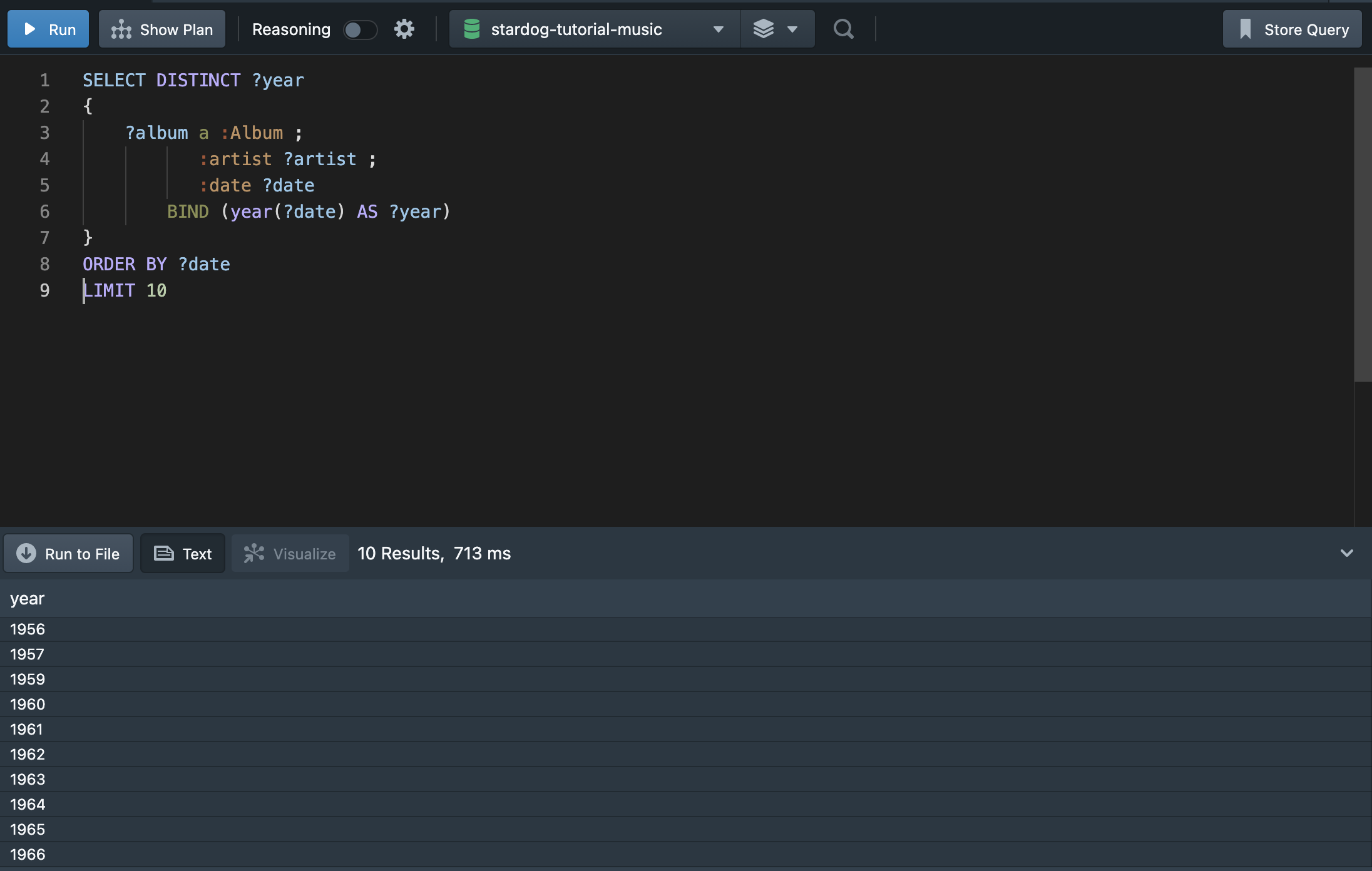
DISTINCT를 써주면 중복 값 없이 유니크한 연도 10개가 출력된다.
5.9 Aggregation
수치 데이터인 경우 집계 함수를 사용할 수 있다. 정규표현식과 다르게, 집계 함수는 SELECT 구문 내에서만 사용가능하다. 집계 함수로는 COUNT, SUM, MIN, MAX, AVG, GROUP_CONCAT, SAMPLE가 있다.
💁🏻♀️ “가장 최근에 발매된 앨범과 가장 오래된 앨범의 발매일을 출력하라”
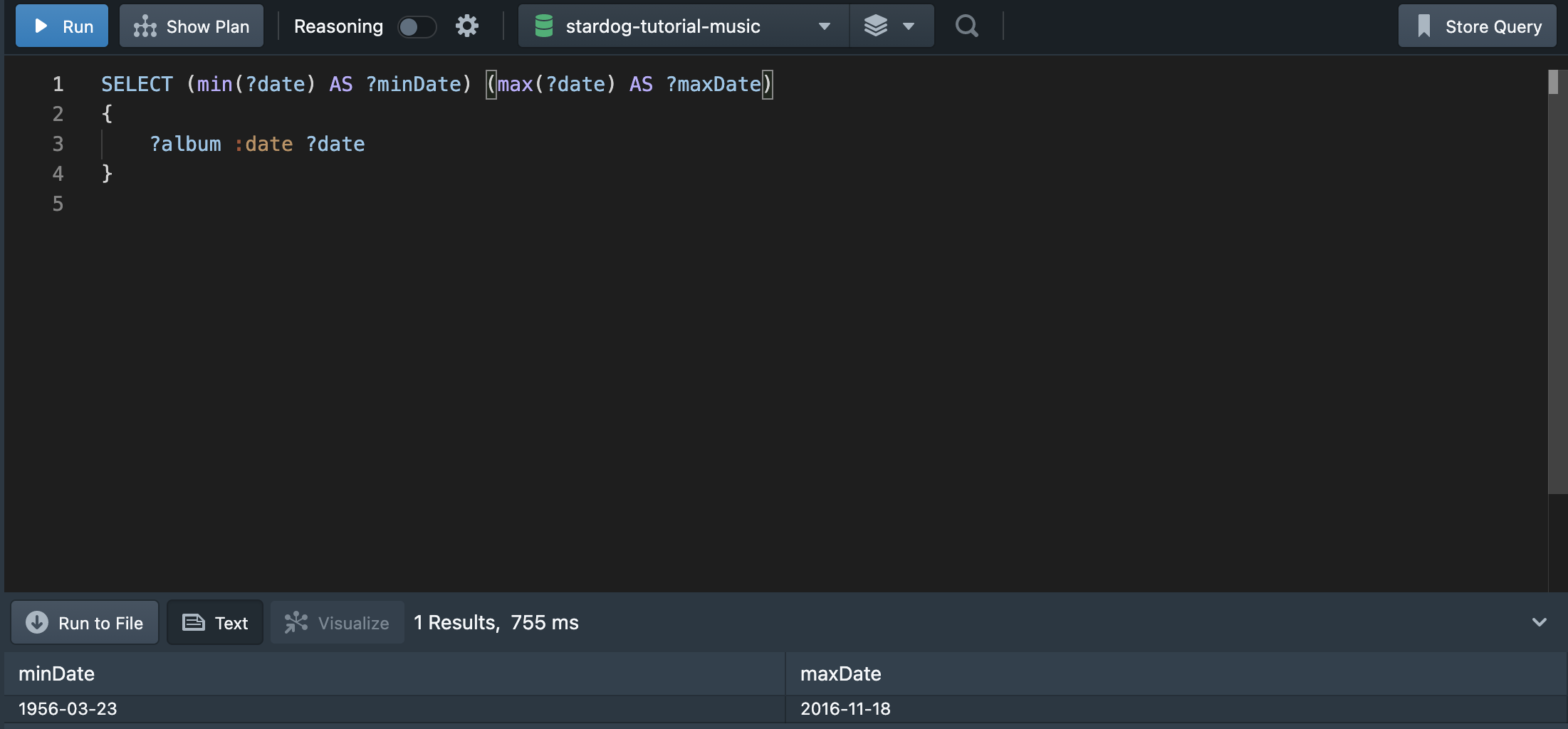
위와 같이 MIN, MAX 함수를 사용해 가장 오래된 앨범 발매일과 가장 최신의 앨범 발매일을 출력할 수 있다.
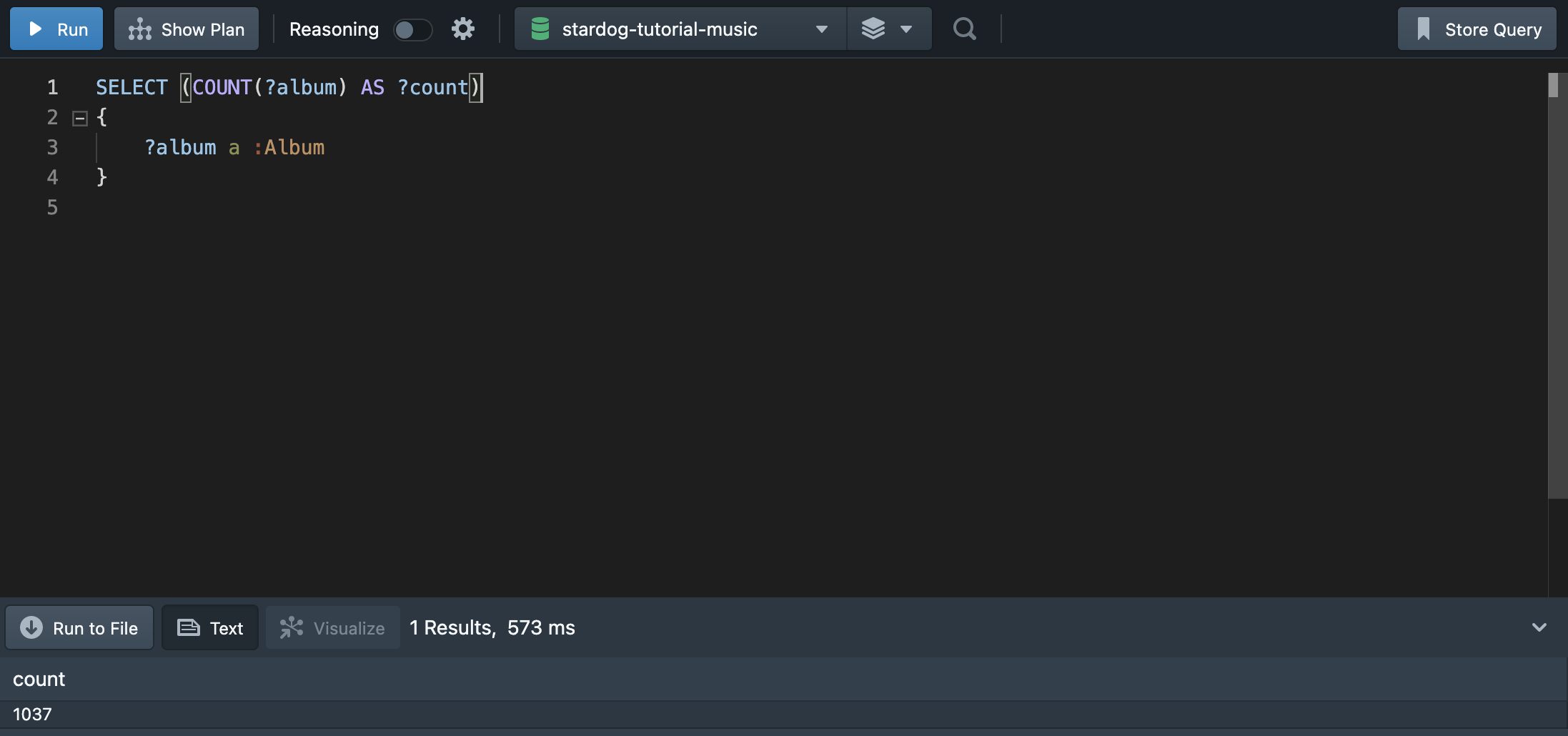
💁🏻♀️ “그럼 음악 그래프에 포함된 총 앨범의 수는? (중복을 제외한다)”
COUNT를 활용하면 음악 그래프 안에 있는 앨범 수를 쉽게 파악할 수 있다.
5.10 Grouping
앞서 하나의 변수에 하나의 집계 함수를 적용해 보았다면, GROUP BY 기능 활용해 1개 이상의 변수들에 대해 다양한 집계 함수를 적용할 수 있다.
💁🏻♀️ “앨범이 발매된 연도를 나열하고, 각 연도에 발매된 앨범 수를 출력하라. 단, 앨범 수가 많은 순으로 나열하라.”
이와 같이 2개의 변수를 출력해야 하는 경우에는 어떻게 해야 할까? GROUP BY를 사용하여 각 변수에 집계 함수를 적용할 수 있다.
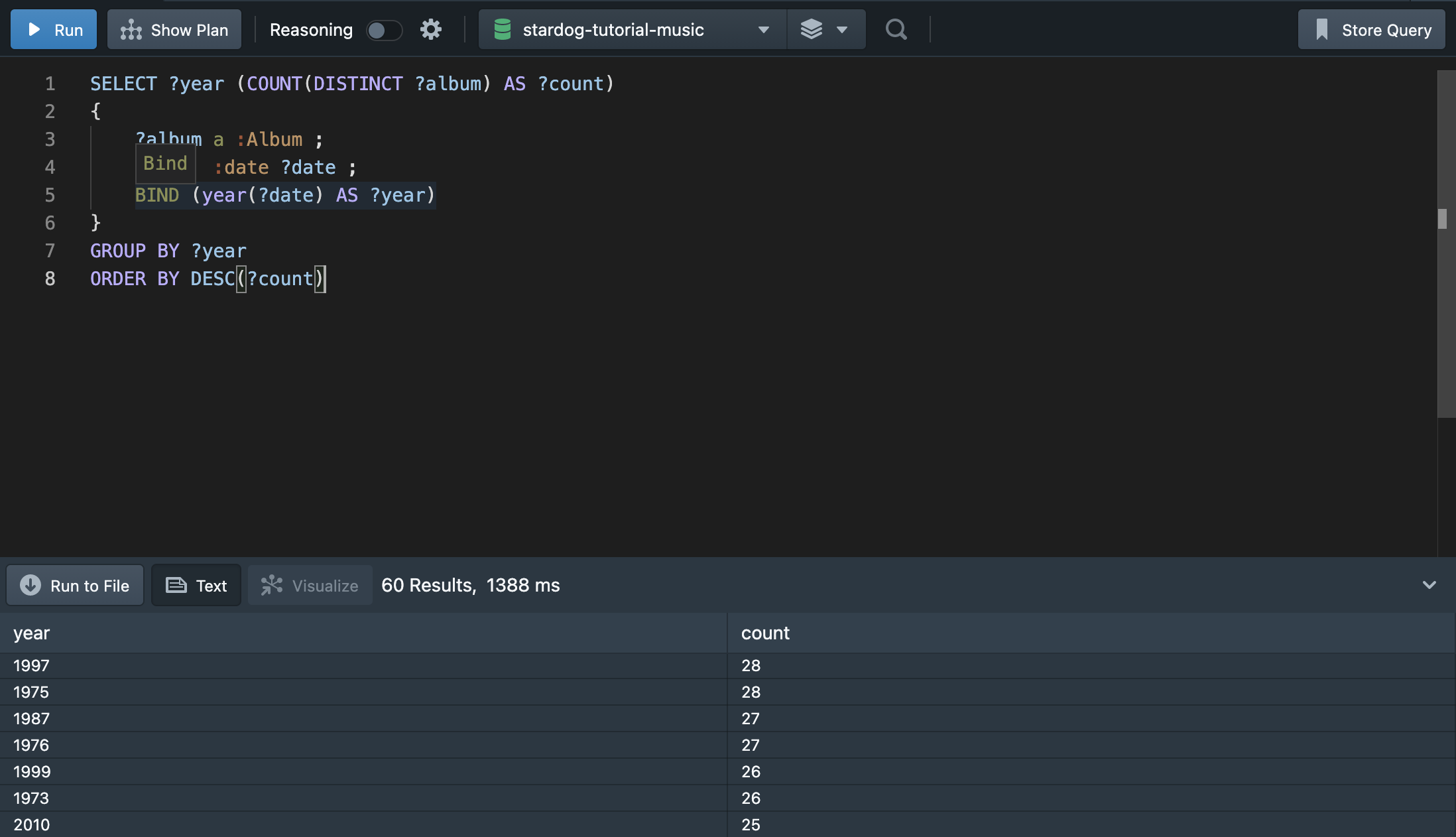
이렇게 ?year을 기준으로 GROUP BY를 해주고, ?count를 기준으로 ORDER BY를 해주면 원하는 결과를 얻을 수 있다. COUNT 안에 DISTINCT를 작성한 까닭은 동일한 앨범 이름이 2개 이상의 발매 일자를 가지고 있기 때문이다.(date 일자가 완전하지 않기 때문이다.) 따라서 쿼리문을 이렇게 작성해주는 것 보다는 데이터를 정제해주는 것이 더 나은 방법이다. 그렇다면 동일한 앨범에서 2개 이상의 발매일을 가지는 케이스는 어떻게 찾을 수 있을까?
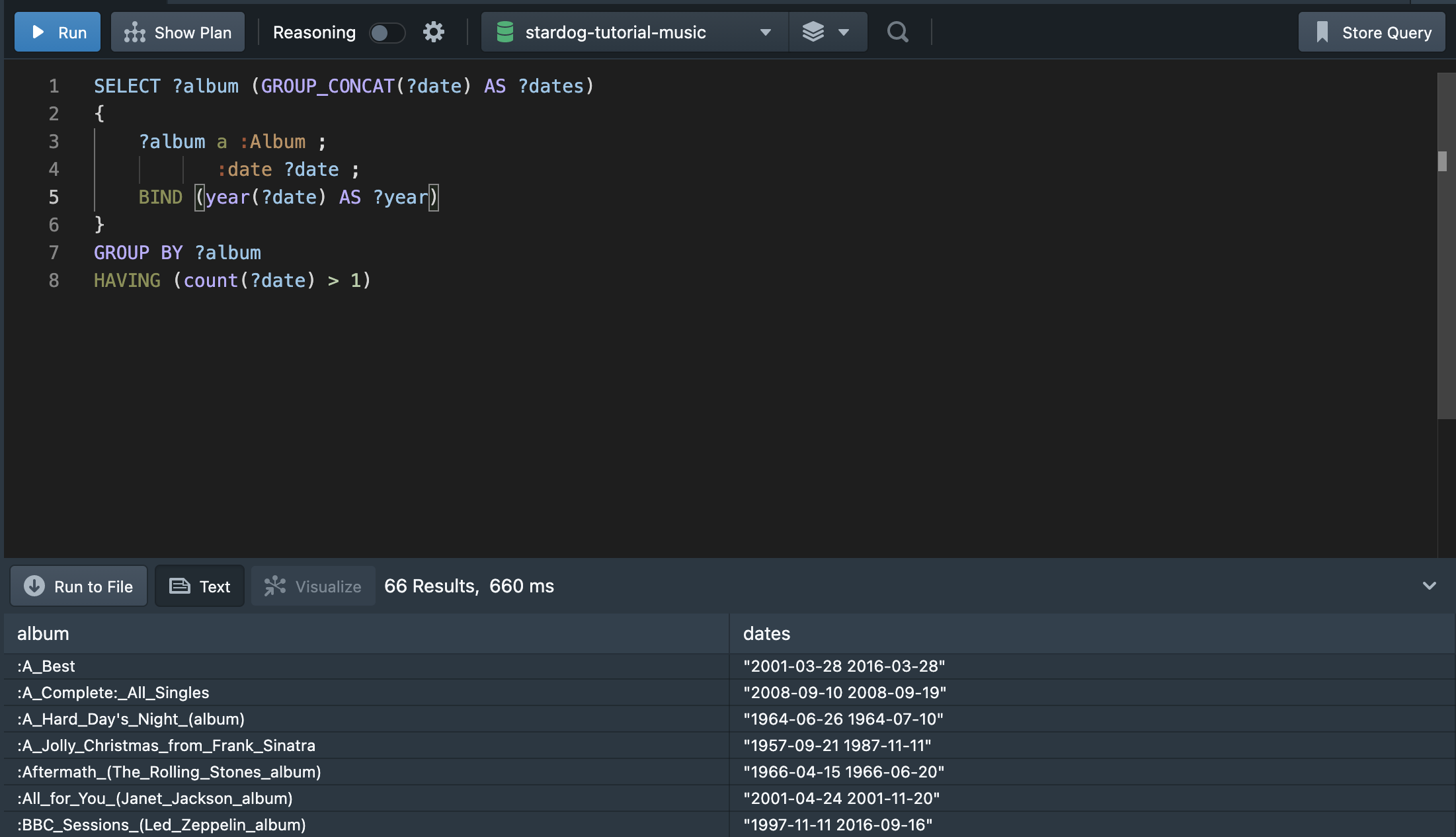
위처럼 GROUP BY에 HAVING이라는 조건을 주어 2개 이상의 발매일을 가지고 있는 앨범명을 찾을 수 있다. GROUP_CONCAT은 데이터 값을 붙여(concatenate) 하나의 값으로 나타내게 한다.
5.11 Subqueries
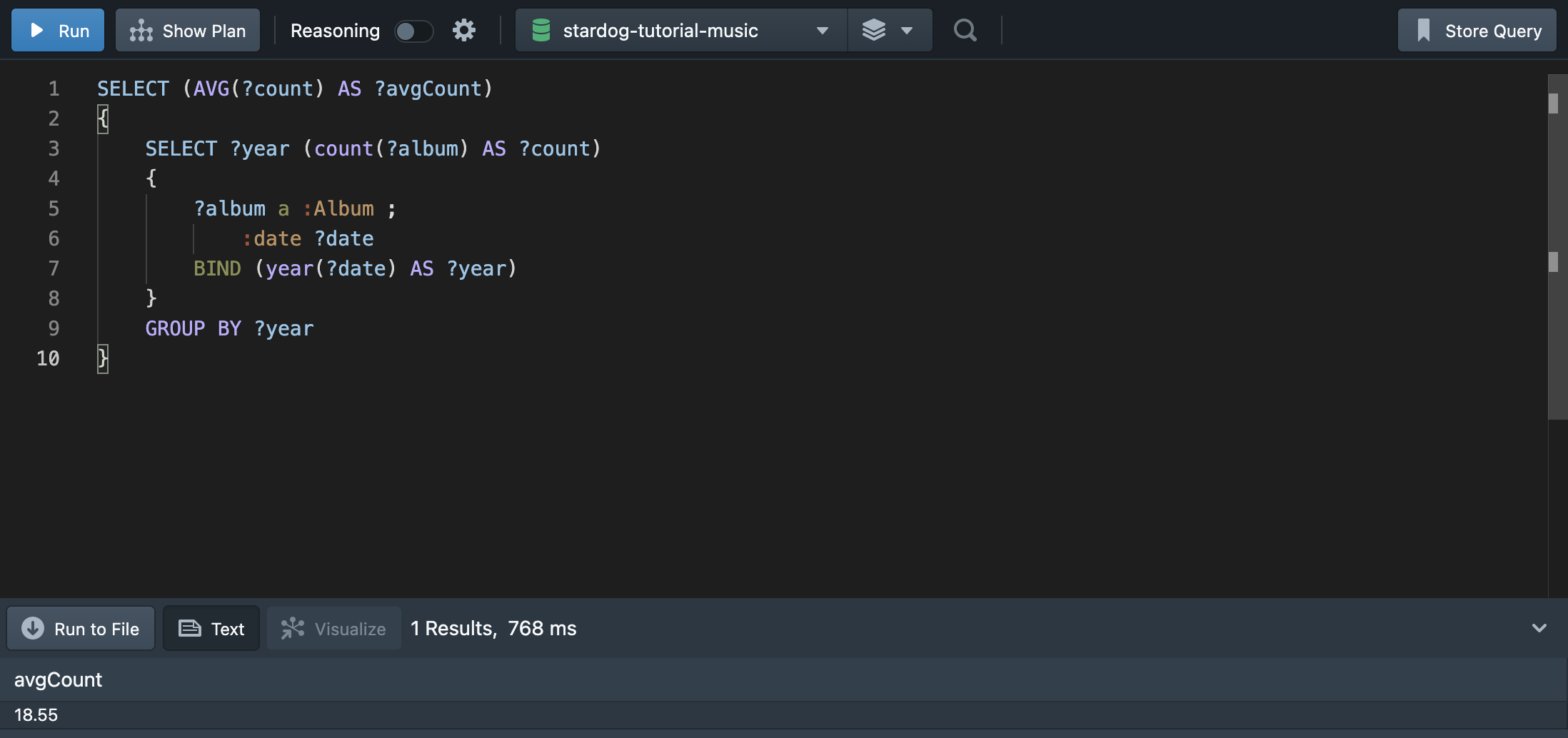
💁🏻♀️ “연도별 평균 앨범 발매 수는 어떻게 구할까?”
평균이라는 집계 함수를 활용해 쿼리문을 작성해보자. 이 경우 쿼리 안에 다시 쿼리를 작성하여 결과를 도출할 수 있다.
5.12 Alternatives
💁🏻♀️ “모든 아티스트의 이름을 출력하라”
음악 그래프 데이터는 Band와 SoloArtist의 클라스로 구성된다. 따라서 UNION으로 각 클라스의 이름을 합쳐 출력하면 전체 아티스트의 이름을 출력할 수 있다. (mysql에서 사용하는 UNION과 같은 기능이라고 보면 된다.)
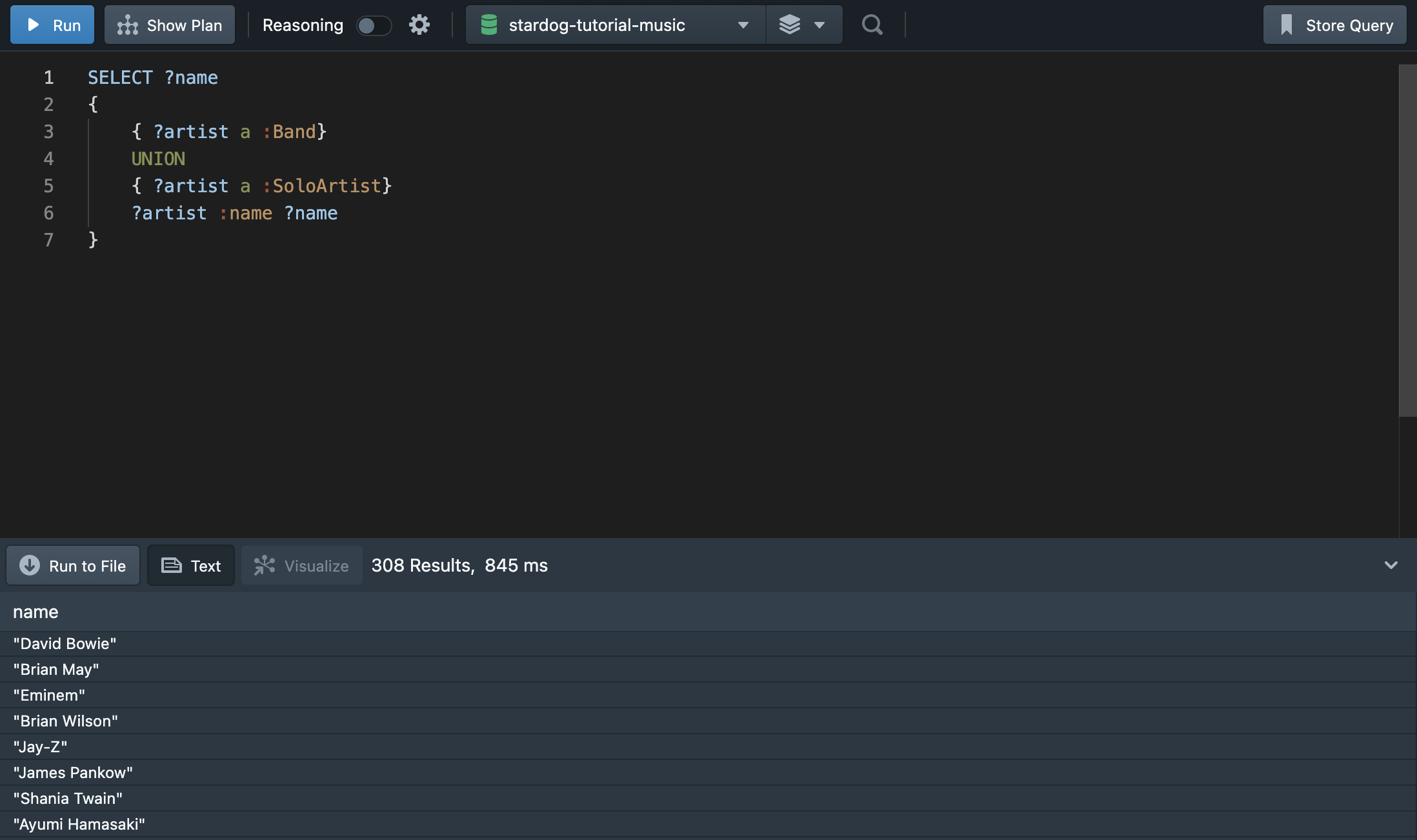
중복 이름을 제거하려면 DISTINCT를 사용하면 된다.
5.13 Optional Matches & Negation
다음의 쿼리는 songs와 그 길이를 결과로 나타낸다.
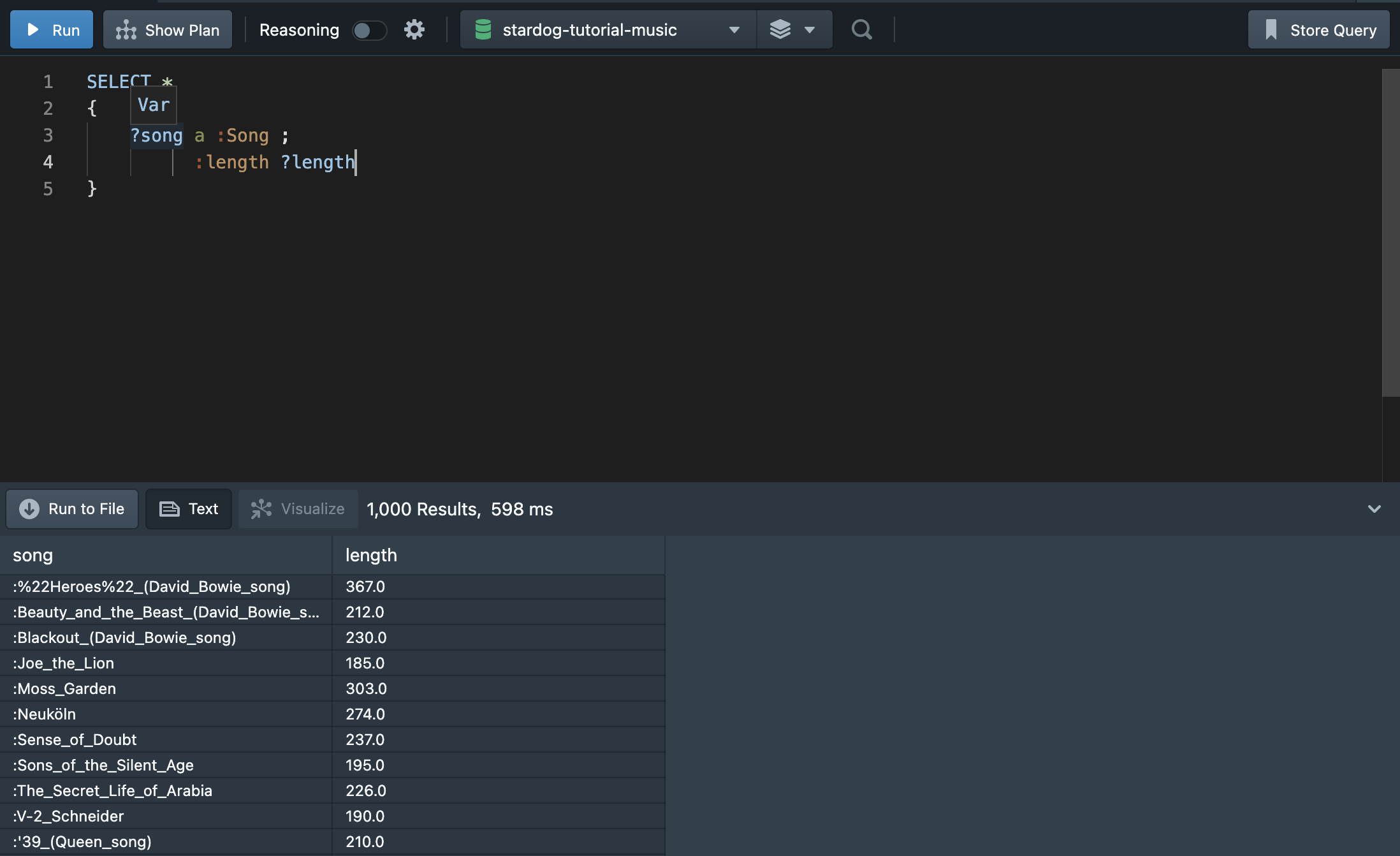
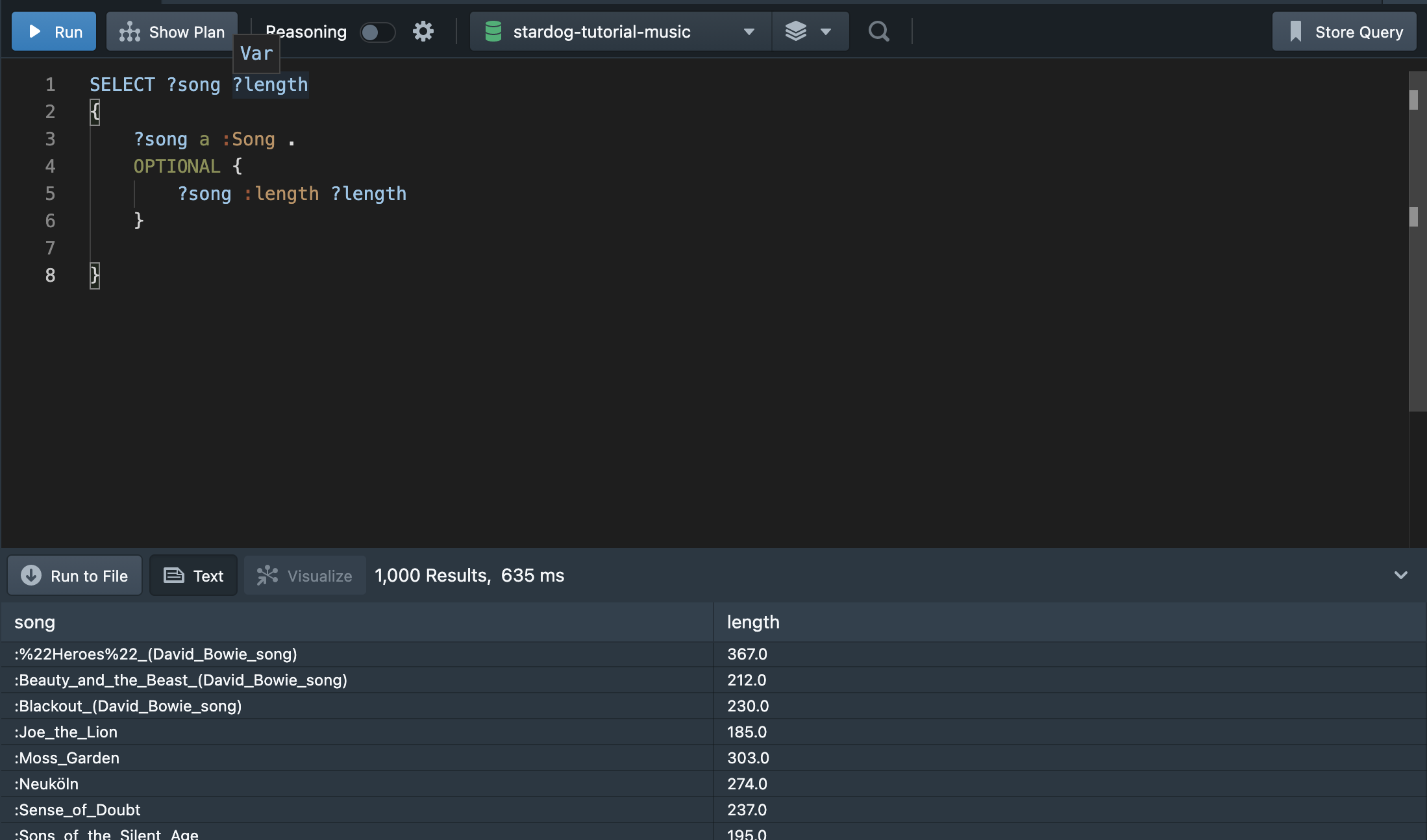
두번째 절을 제외하면 3,749개의 곡 정보를 가져오나, 두번째 절을 포함하면 3,640개의 곡을 출력한다. :length 정보가 없는 경우, 정보를 출력하지 않게 된다. 이런 경우 OPTIONAL을 사용하여 쿼리문을 작성할 수 있다.
:length 정보도 출력하려면, 아래와 같이 OPTIONAL 방식을 사용할 수 있다.
만약 :length 정보가 없는 곡 정보만 출력하려면 아래와 같이 FILTER를 사용하면 된다.
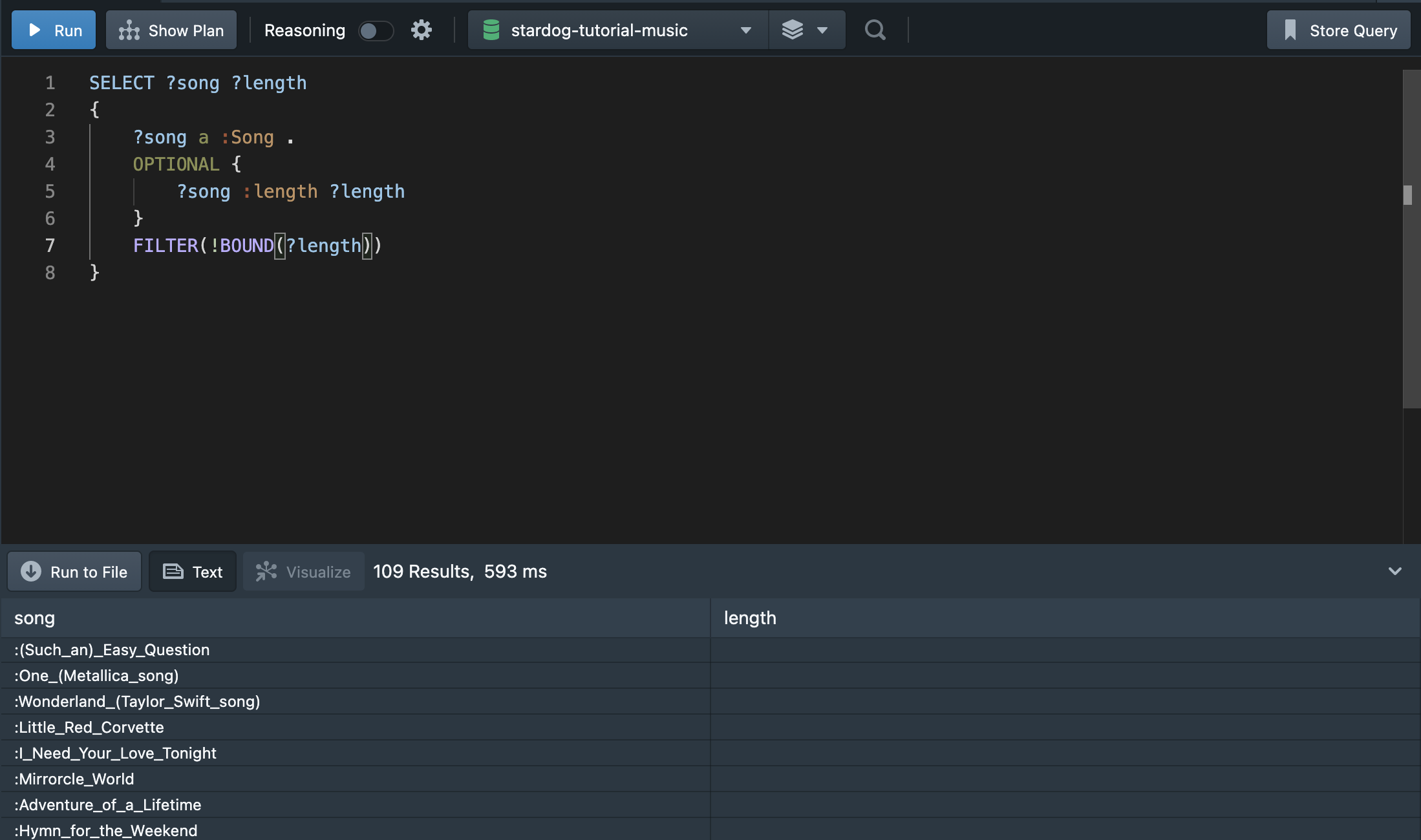
BOUND는 값이 있는 경우 TRUE를 출력한다. !BOUND(?length)는 반대로 ?length 값이 없는 경우에만 값을 필터링한다. 또는 아래와 같이 FILTER NOT EXISTS를 사용하여 값이 없는 결과만 출력할 수 있다.
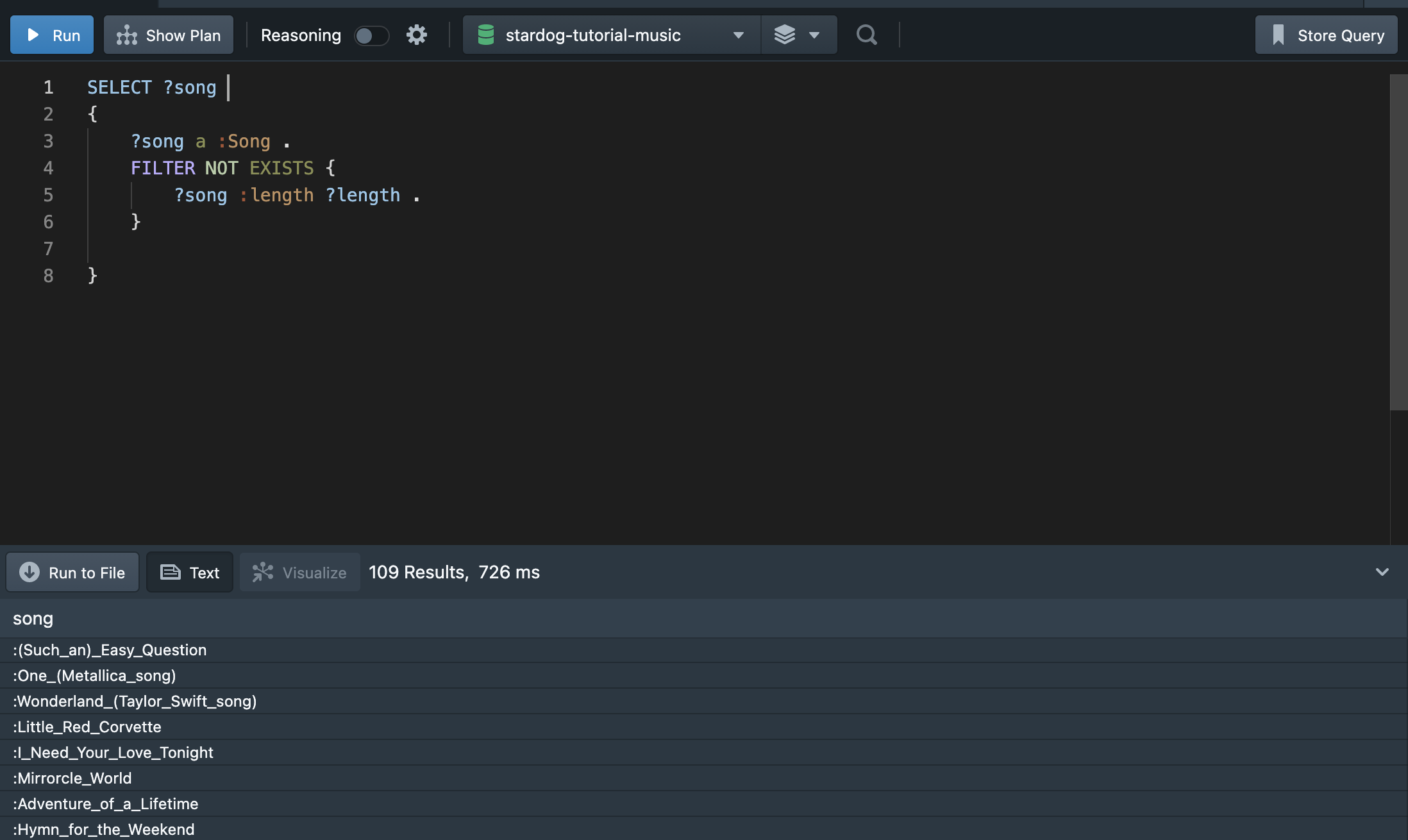
6. SPARQL Query Forms
SELECT 쿼리 이외에도 SPARQL Query Forms가 있다. 그러나 이 경우 테이블 형태로 결과가 출력되지는 않는다.
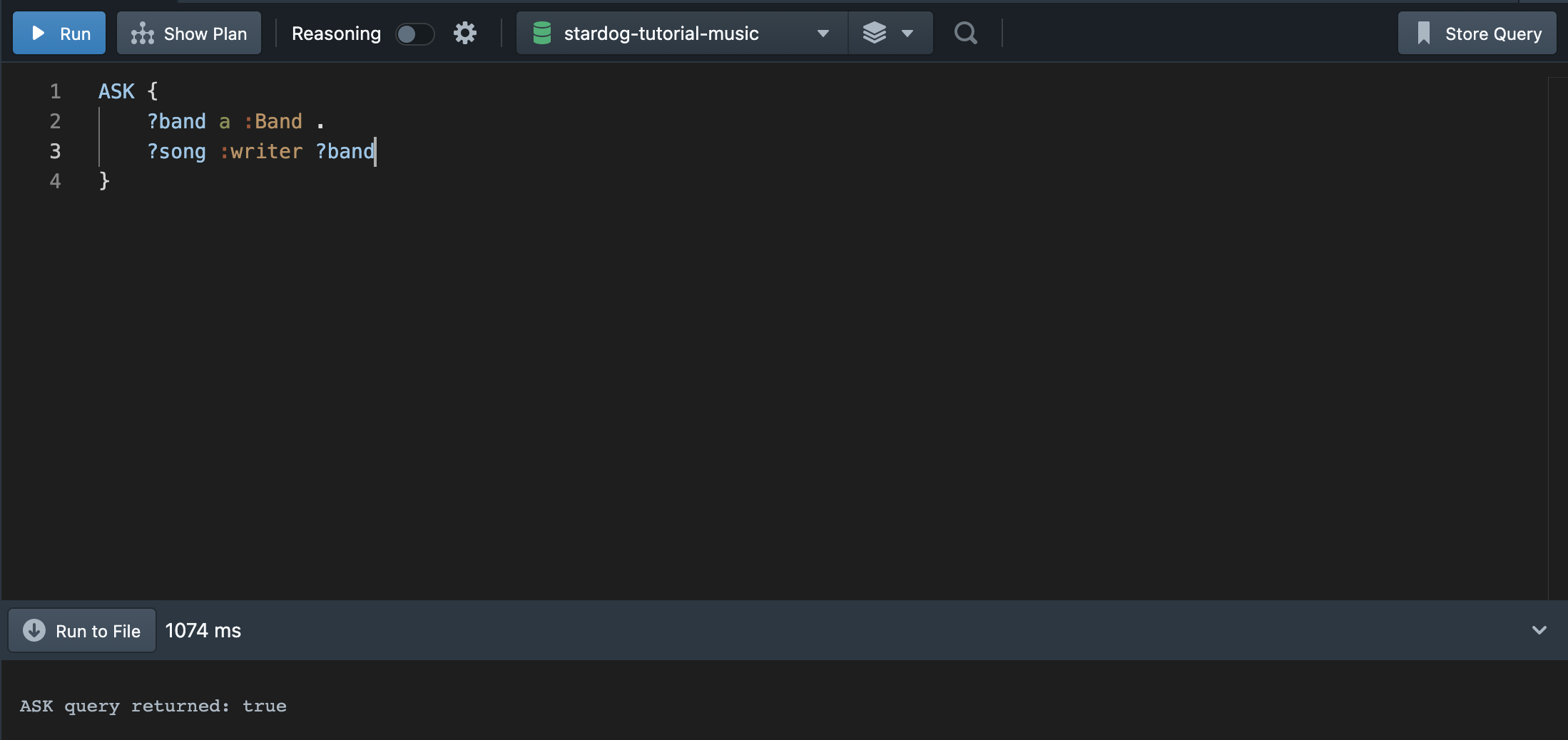
6.1 ASK Queries
ASK Queries는 WHERE 절에 부합하는 패턴을 boolean 결과로 출력한다. 아래와 같이 물어볼 수 있다.
💁🏻♀️ “곡을 만든 아티스트 중 밴드가 하나라도 있는가?”
이 질문에 대해 ASK로 물어볼 수 있고, TRUE or FALSE로 결과를 리턴한다. 이 경우 SELECT로 구체적인 데이터를 쿼리하기 이전에 값의 유무를 탐색하고자 사용할 수 있다.
6.2 DESCRIBE Queries
DESCRIBE Queries는 RDF 그래프를 반환한다. 노드에서 트리플 구조가 반환되는 것은 SPARQL 설명에서 미리 설명되어 있지 않고, 사실상 시스템에 의존적이다. DESCRIBE 이행은 노드에 대한 모든 엣지(edges)를 설명한다.
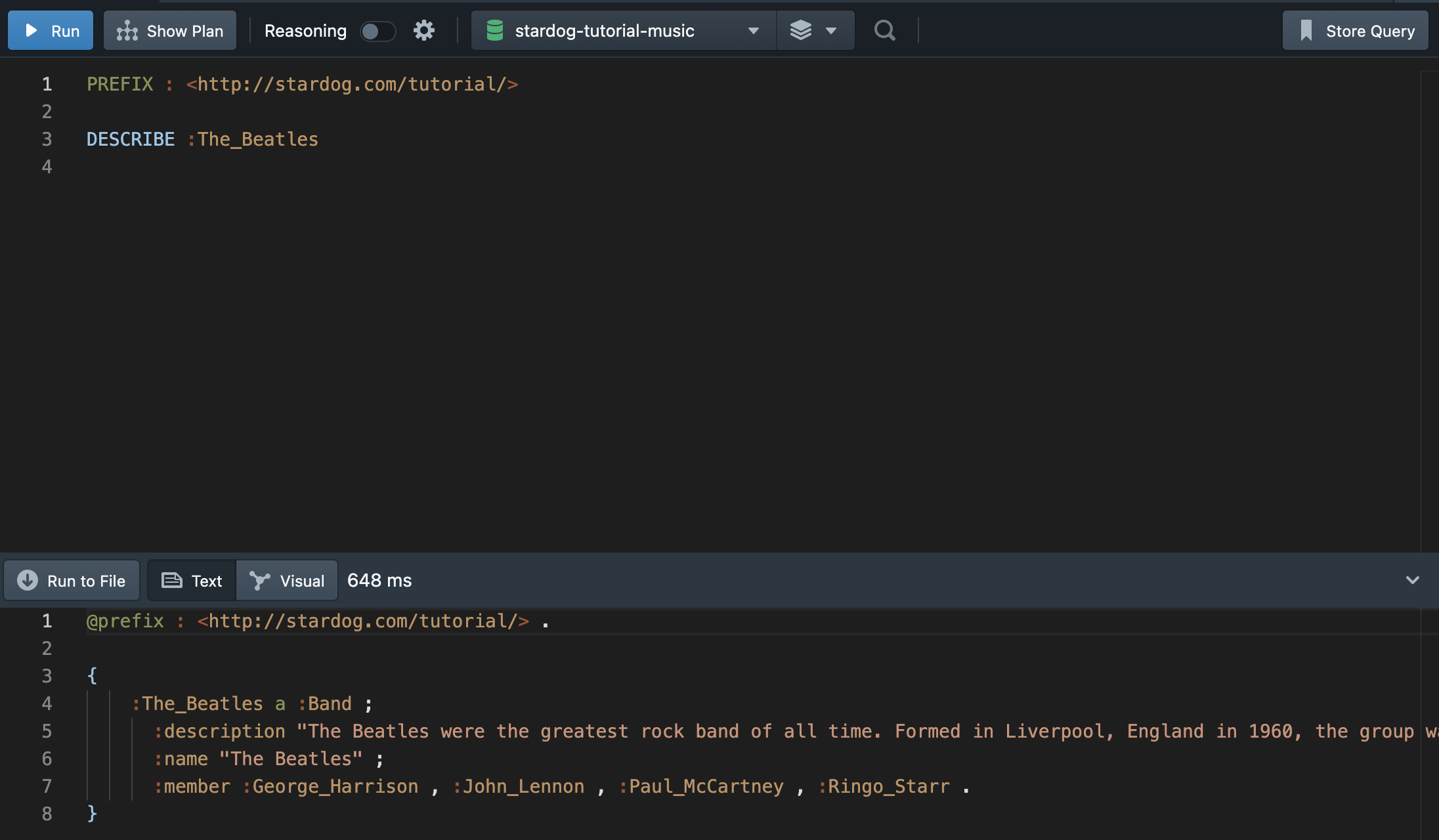
DESCRIBE 쿼리는 쿼리하는 RDF 그래프의 구조를 모를 때 가장 유용하게 사용할 수 있다. DESCRIBE를 통해 트리플 구조에서 사용된 용어들을 빠르게 확인할 수 있다. 당연히 SELECT * { :The_Beatles ?p ?o }와 같은 목적을 수행한다.
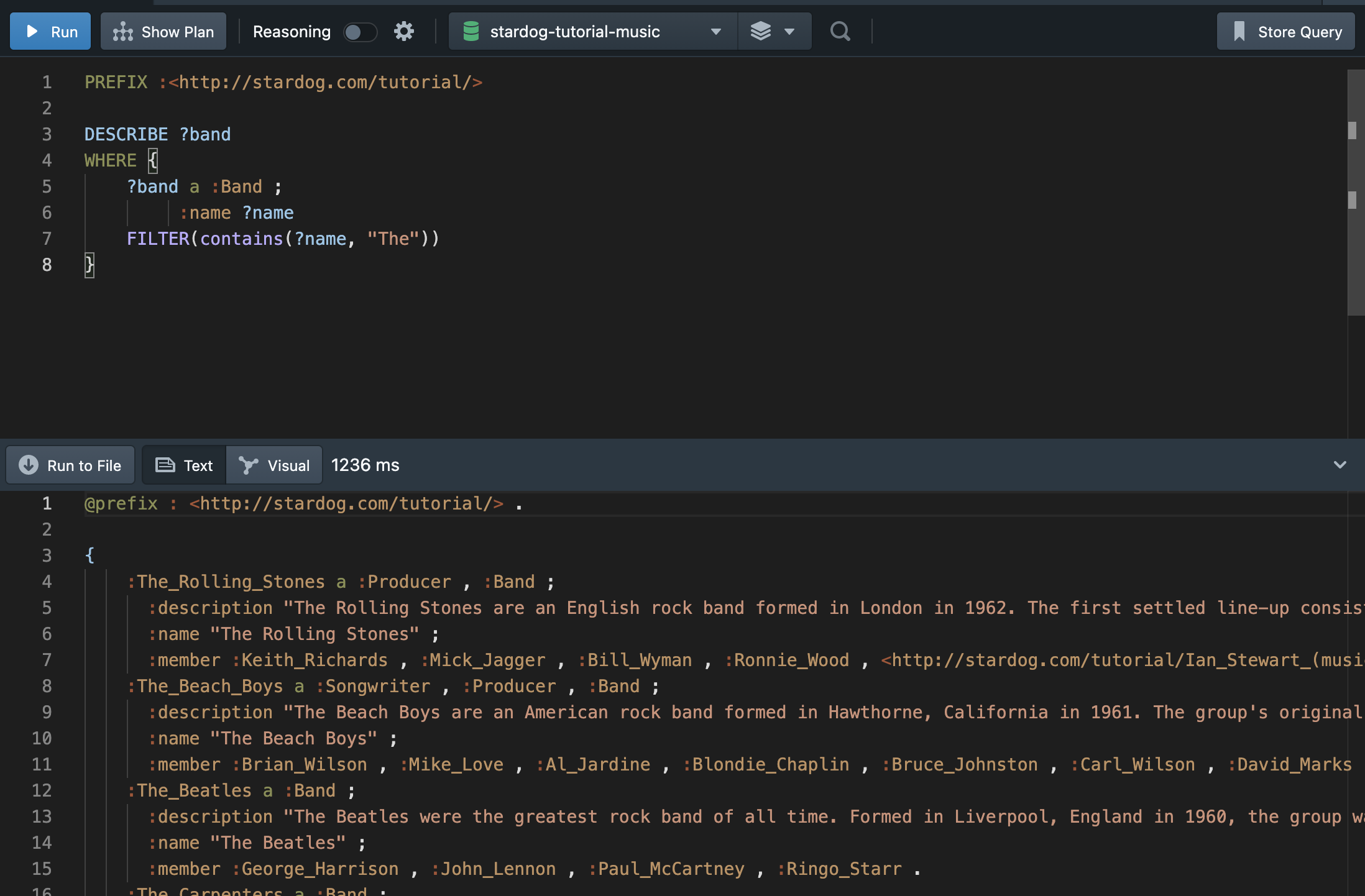
DESCRIBE를 사용할 때 WHERE절로 조건에 맞는 변수에 대한 구체적인 정보를 얻을 수 있다. 다음의 쿼리는 “The”가 포함된 이름을 가진 모든 밴드에 대한 구체적인 정보를 설명한다.
6.3 CONSTRUCT Queries
CONSTRUCT 쿼리는 WHERE 절 안의 패턴과 매치되고, 결과로 RDF 그래프를 반환한다. 만약 WHERE 절 안에 트리플 구조만 존재한다면, 축약된 구문을 사용할 수 있다. 예를 들어, 밴드와 그 멤버들을 반환하기 위해서는 아래와 같은 쿼리를 작성하면 된다.
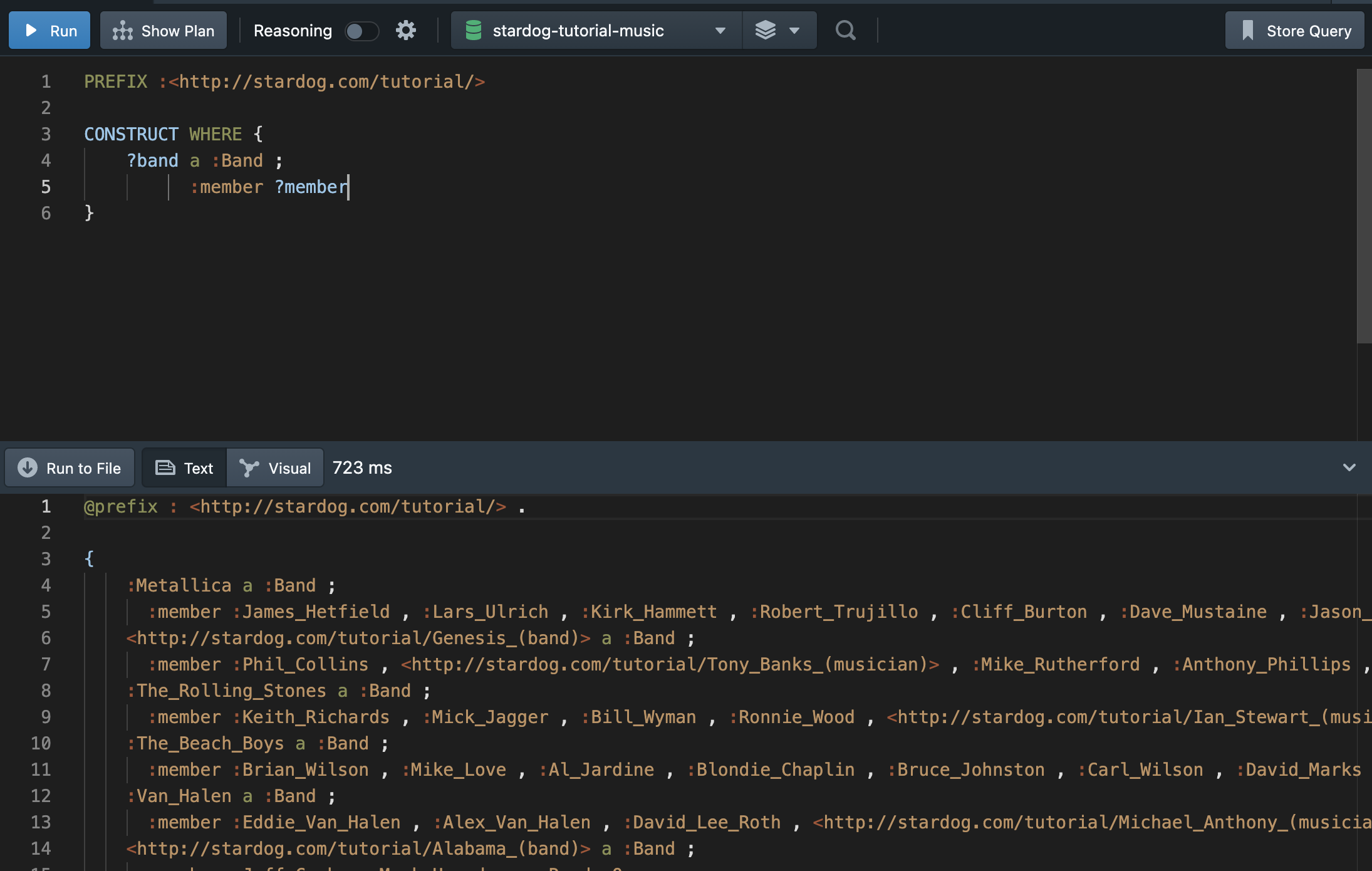
WHERE절에 맞는 트리플보다 다른 트리플 세트를 반환할 수 있는 CONSTRUCT 템플릿을 구체화할 수 있다.
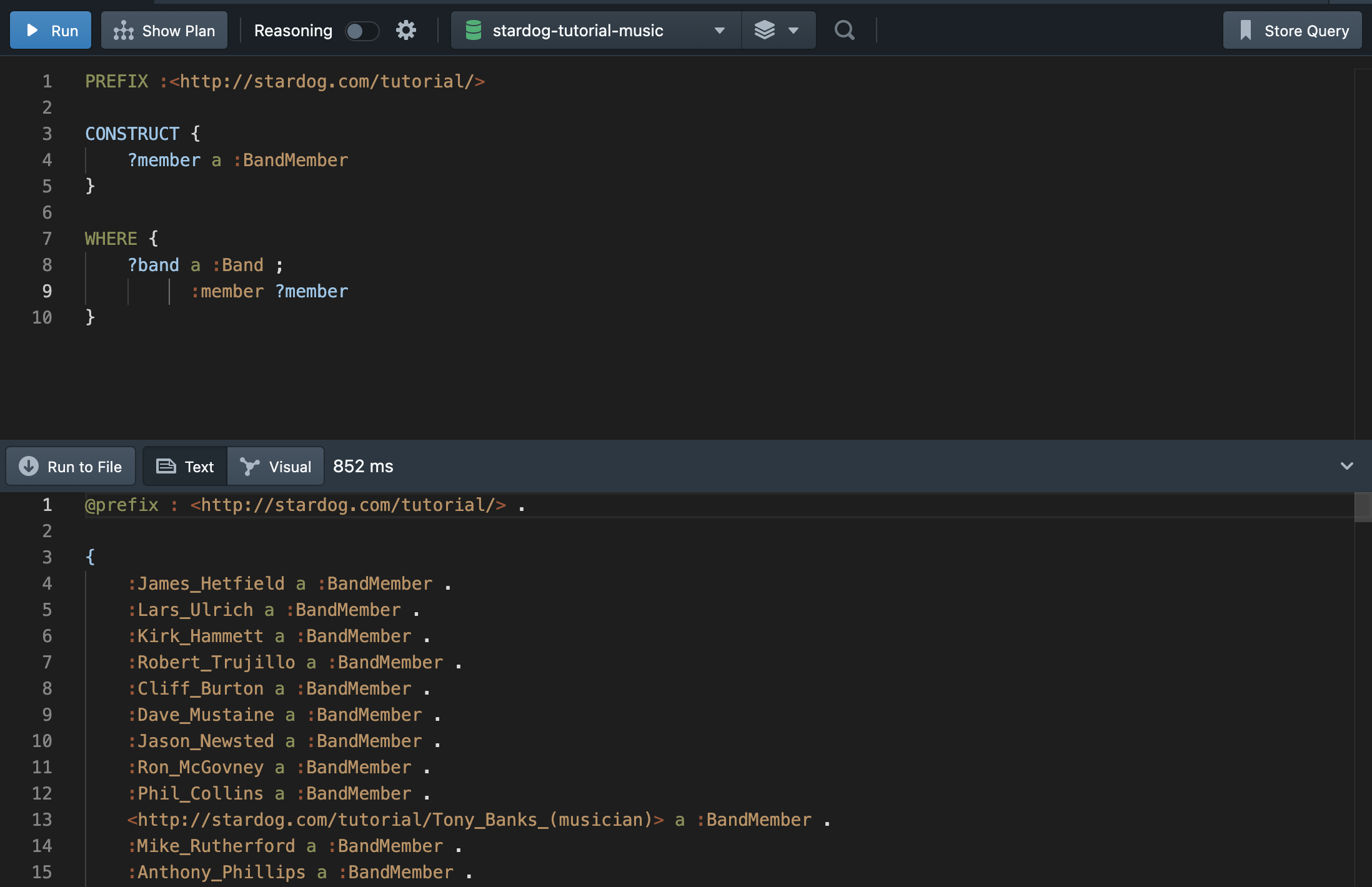
이렇게 구체화하면 :BandMember와 같이 그래프에 없는 데이터도 트리플 구조도 쿼리로 반환할 수 있다. CONSTRUCT 쿼리들은 지금까지 우리가 본 다른 query forms와 같이 읽기만 할 수 있고, 수정할 수 없다. 만약 RDF 그래프를 수정하기 위해서는 다음에서 설명할 update 쿼리를 사용할 수 있다.
6.4 UPDATE Queries
만약 우리가 쿼리의 결과에 기초해 데이터베이스에 트리플을 집어넣고 싶다면, INSERT 쿼리를 사용할 수 있다. 다음 쿼리는 위의 CONSTRUCT 쿼리와 비슷하나 데이터베이스에 단순히 트리플 결과를 넣을 수 있다.
또한 데이터베이스로부터 트리플을 삭제하기위해 WHERE절을 사용할 수 있다.
:length 속성이 곡의 길이를 구체화하기 위해서 정수 범위를 사용할 수 있다. 이는 많은 경우 간단하면서도 좋은 방법이지만, XML 스키마 데이터타입인 xsd:dayTimeDuration을 사용하는 것이 길이와 연관된 시간 unit의 모호성을 피하는 데에 더 나은 방법이다. 그래서 만약 duration 값에 모든 :length 값을 대체하기를 원하면, 아래와 같이 쿼리를 작성할 수 있다.


Leave a comment